As Dennis Ritchie had once decreed ...
There shall be Unix, and there shall be syscalls
And now syscalls are forever ingrained as a part of POSIX the only standard means of communication between user-space and the kernel.

While I am not a fan of WinAPI (like seriously, who names their functions CreateProcessWithLogonW 🥴),
it's not that syscalls are without their problems. They are slow, cannot have granular permissioning
mechanisms, cannot easily be sandboxed, among other things.
Join us as we explore a bunch of different solutions for a some problems that syscalls have ...
Privbox - Syscalls without Context Switch
Syscalls are slow. We use them sparingly, try to collate them as much as possible and simply avoid them if we can, well, avoid them.
char buf[1024];
for (int i = 0; i < sizeof(buf); i++)
read(stdin, buf + i, 1);
If the code above makes you want to scream and rant at your screen, then yeah, you know that syscalls are slow.

The biggest overhead associated with syscalls is the context switch inherent with it. The overhead
associated with the syscall instruction is considerably higher than with a plain call, since
several registers must be loaded with new values (including changing CPL to 0). The OS switches to
a new stack (typically), cache-misses are likely to follow, and ...
Spectre and Meltdown enters the chat
Other than knowing that these are "side-channel attacks" (whatever that means), I have no idea what these truly are. Yes, Intel (and AMD) screwed up big time, CPU's suddenly became super exploitable and all hell broke loose. You know you have done messed up when you have to go around begging OS vendors to fix your hardware problem with software.
And oh boy, were these fixes bad.
Linux needs to flush the indirect branch predictor state on syscall entry to combat Spectre. As for Meltdown, Linux adopted "page-table isolation", which is just a fancy way for saying, "we switch page tables every time we make a syscall". And as if this wasn't bad enough, the TLB needs to be flushed as well.
Syscalls just got even slower.
Now, I'd admit that this is a bit of a missed blame scenario. It is not that syscalls are inherently
slow. Rather, switching from CPL 3 to 0 is slow and has gotten even slower thanks to these CPU
bugs. What if we could make syscalls without changing CPL?
That is precisely what Privbox allows us.
What is Privbox?
Privbox is a code sandbox which runs in CPL 0, but with two restrictions, making the execution
"semi-privileged":
- The page-tables are designed so as that all user-space memory is marked non-executable except for the special areas designated for privbox. This disallows code to "escape" from the privbox. On the other hand, kernel area memory has its usual permissions, so that syscalls can be executed without any additional overhead.
- The code in the privbox is instrumented at compile-time and the instrumentation can be verified by the kernel. The instrumentation prevents the privboxed code from reading arbitrary kernel memory, jumping to arbitrary kernel code and execute privileged instructions.
Effectively, Privbox ensures user-mode style code execution in CPL 0. This way syscalls don't have
any extra overhead over normal function calls. On the other hand, the instrumentation adds an overhead
to many other instructions. It has been found out that this cost isn't too bad even if we instrument
the entire codebase, because syscalls are normally so expensive. If we are to be more efficient,
we can single out sections of code that are "syscall-intensive", just instrument them to use Privbox
and dynamically link the ELF file.
Semi-Privileged Execution
To be honest, "semi-privileged" execution is a misnomer - in all truth, it should be called
"you-ain't-got-no-privileges" execution. Although, the code runs in CPL 0, it cannot access
any kernel code or perform privileged instructions (via instrumentation). The page tables are configured
to disallow execution of most of user-mode memory (but it still has read-write access). A separate
stack is used privbox mode, utilizing the interrupt stack table (IST) option in x86_64.
The privbox-mode is entered via a function and is returned from via another function, which is callable
only from within the privbox (this is ensured by the page-table config). For making syscalls,
the usual syscall instruction is not used. A custom function "gate" is used, which emulates the
operation of syscall by setting up the registers and stack to pass the requisite variables.
Instrumentation
The real elephant in the room is of course the instrumentation. While there are many gory details to it, I am going to talk only about the gist of it.
Firstly, there is something called "chunking". This is made to ensure that the finally generated code
can be verified. The problem with x86_64 instructions is that they have variable-length encoding.
So quite literally, for a given code block, it could mean a different set of instructions depending
on where you start reading it! To get around this, the code that runs in a Privbox is partitioned into
32-byte chunks, which is probably padded in the end with nop instructions (these take up 1 byte each).
There are four categories of instructions that need to be instrumented:
-
Load/store instructions: The target of the load/store instruction must be ensured to not access kernel memory. There is a remarkably simple trick to do this - clear the MSB of the address. In x86-64, the memory layout is as follows:
Thus if we clear the MSB of a user-mode address, then we get back the same address. If we do that for a kernel-mode address, then we get a non-canonical address, which will trigger an exception. And voila! The rest is, as we engineers like to say, an implementation detail.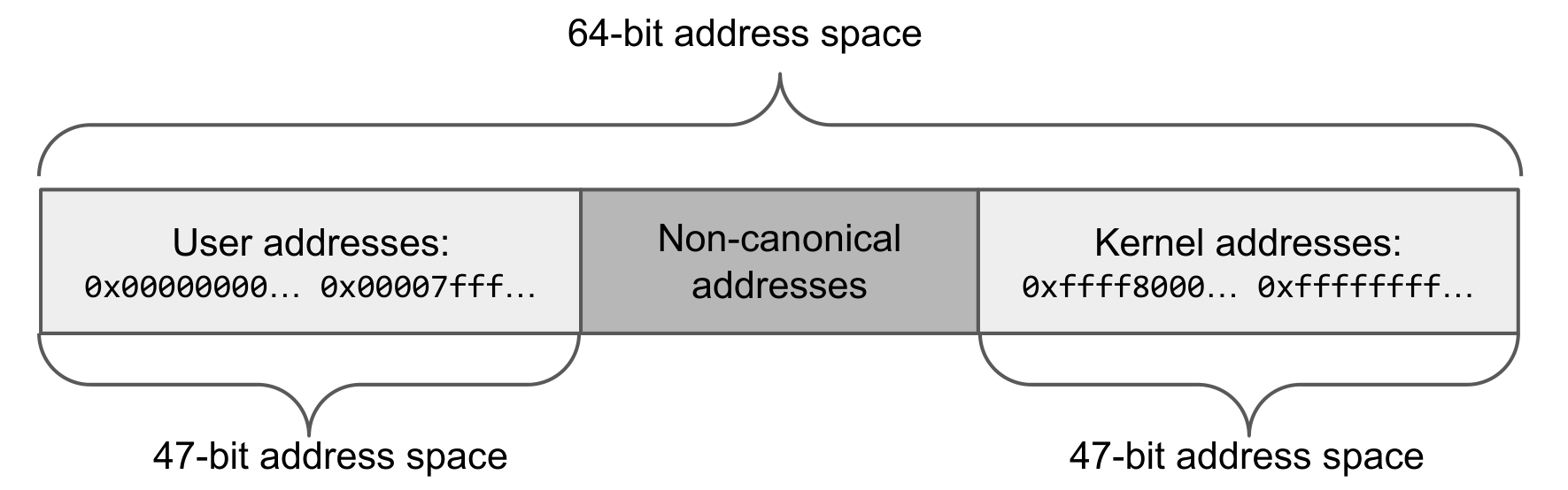 Figure 1: x86_64 memory layout
Figure 1: x86_64 memory layout -
Control-flow instructions: Here, we need to do the same clearing-the-MSB trick for branch targets. In addition, we need to ensure that we don't branch to the middle of a chunk. This could be a cool way to introduce malicious instructions. To this end, we clear the bottom 5 bits of the branch target as well, thus making sure we branch only to a chunk boundary.
-
Return instruction: A
retinstruction can be used to jump to random places, since all we need to do is to place the malicious address on the stack andretwill cause control to jump to there. Thus, we need to replaceretwith a bunch of instructions which perform the same steps as it, also sanitizing the return address in meanwhile. -
Call/jump instruction: Quite similar to above, the call/jump target is sanitized by clearing the MSB and the bottom 5 bits. (And by now, I'm quite bored of describing this)
Results
Disclaimer: I have not run the code and the results I quote are due to the original authors. Make what you want of it.
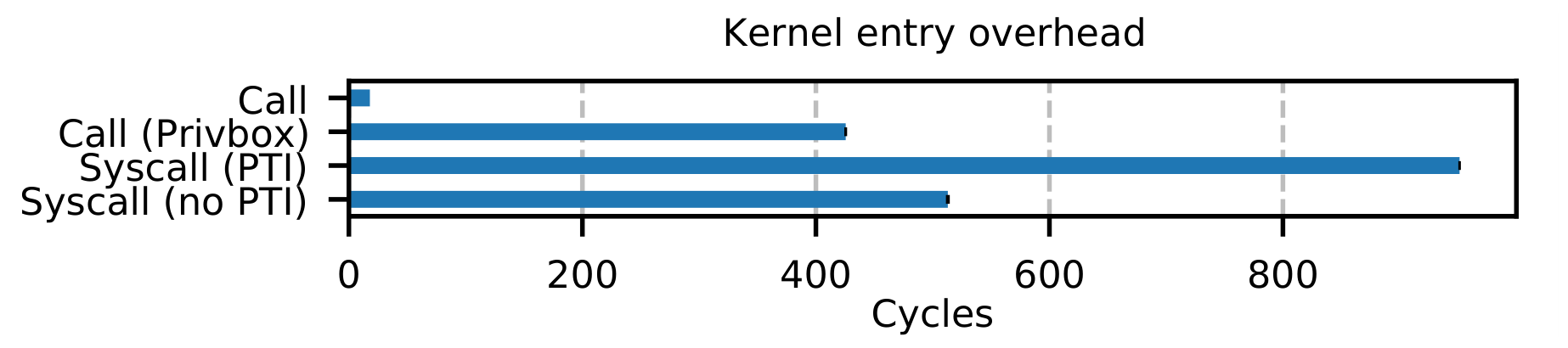
As is expected, Privbox syscalls are faster than regular ones, being about 1.2 faster, while it is 2.2 times faster for Meltdown affected systems. It is still slower than regular function calls since there is an overhead associated with switching the stack and loading additional registers.
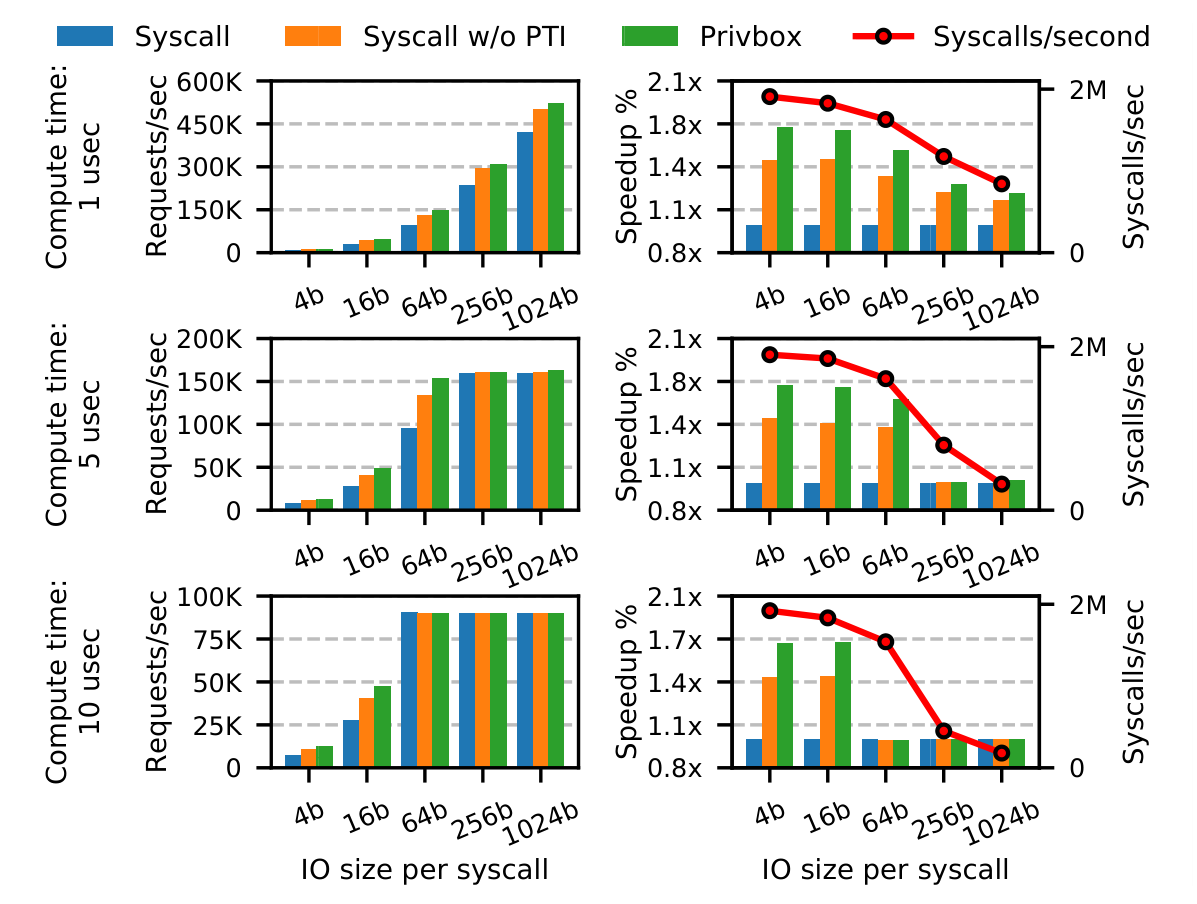
For testing IO syscall performance, the authors devised a programs which has a compute-intensive main thread and another thread that handles IO requests. Thus there are two "parameters", the amount of computation and the size of IO request. As the above figure describes, the best best speed-up is obtained for smaller IO requests, where the syscall invocation time becomes a significant overhead. If we have larger IO requests (equivalent to the collation of requests), the gain becomes less as the dominant factor becomes the IO service time.
In addition, the authors test Privbox on a bunch of real-world applications (as opposed to synthetic benchmarks). A similar speed-up is noticed in all of them. I will highlight one of them - the performance of a Redis server.
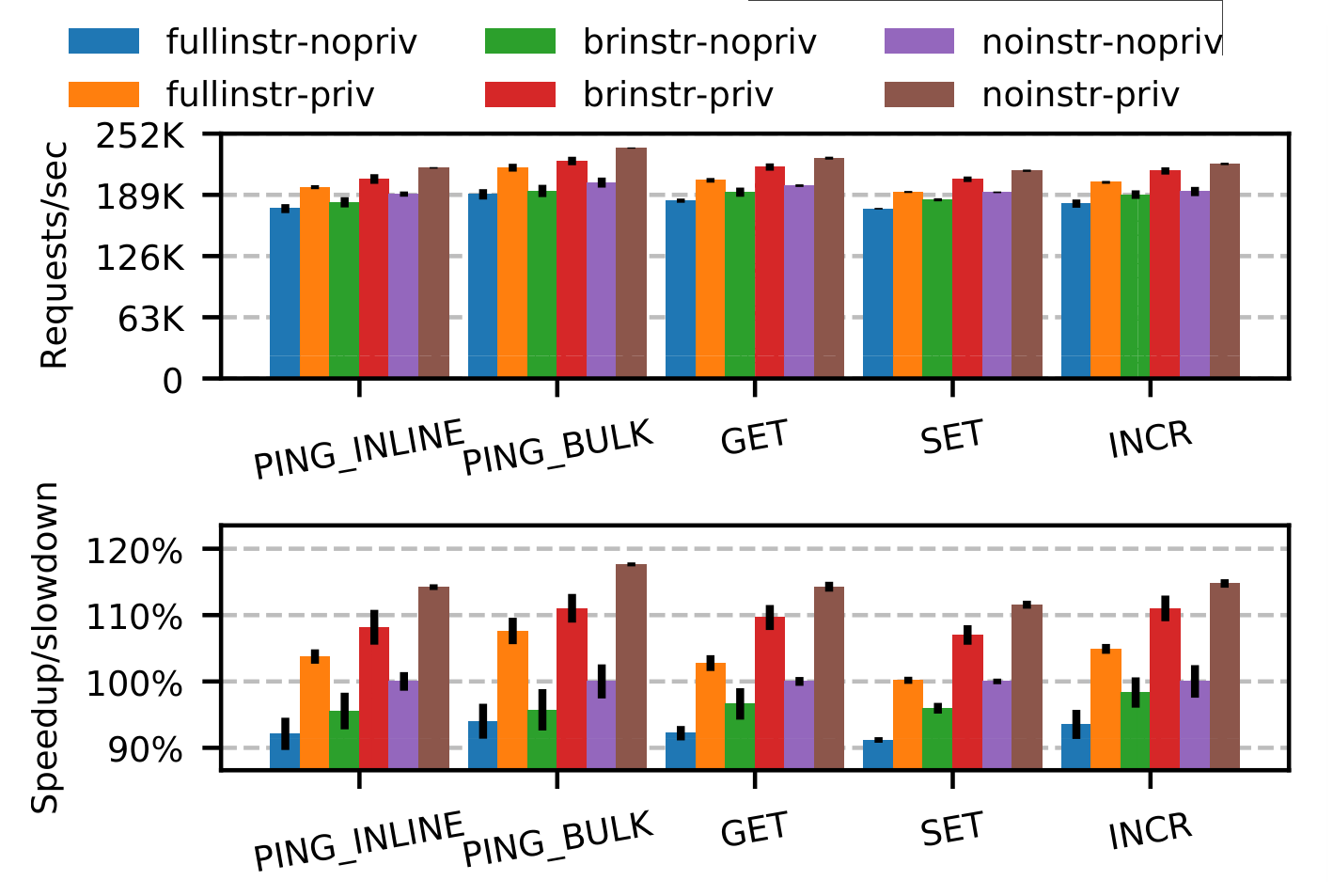
This graph is a bit involved. The nopriv vs priv labels indicate that the code is running
normally versus running in a Privbox. The noinstr version indicates absence of instrumentation,
fullinstr indicates complete instrumentation of code, while brinstr indicates instrumentation
of only control flow instructions. The last category is theorized by the authors to simulate hardware
on which load-store instrumentation can be avoided by special hardware flags (which doesn't exist,
so this bit is effectively a simulation).
Not unexpectedly (I mean it's a paper, so the result has got to be positive), there is a throughput increase on using Privbox. This increase happens irrespective of the amount of instrumentation. Of course with lesser instrumentation, there is better performance.
Critique
Privbox is essentially a sane implementation of Terry Davis' (the guy who made TempleOS) rant that all OS's should have a ring 0 design, and that Linux is stupid because it doesn't. Of course, his argument doesn't work well for people who don't write all the software that they use themselves! Privbox assumes that the code is un-trusted and malicious, and takes requisite precautions, upholding all of its security invariants.
In practice, the performance bump is obtained only in code that is syscall-rich (which isn't always the case). So, in order to make Privbox work well for many applications, they have to be modified to have the "IO-thread-Compute-thread" style architecture, where the IO bound tasks are processed as requests in a separate thread. Then only the code for this thread can be instrumented and run in Privbox.
The instrumentation is performed by a modified LLVM codegen backend. This limits usage to languages having an LLVM-based compiler (which is probably most system programming languages now anyway). Also, for languages that don't compile to native code, the Privbox technique may or may not work. Some languages separate out OS dependent code (which involves syscalls) to C code and have an FFI layer to communicate with the rest of the language. For these languages, it may be possible to Privbox these syscall handlers.
sysfilter: automated filtering of syscalls for user software applications
Paper link here. All figures are taken from the paper.
Let’s start with a simple real-world example. Think about any organizational hierarchy. Say a university. Any enterprise resource management software for the university will have levels of security and permissions for different actors in the software; you may not want students to be able to modify grades; and similarly you may not want the salary credit system to fall into the hands of employees. In the field of security, in general and information security in particular, the principle of least privilege forms one of the core fundamentals. The above is a high-level example for the same.
Think about different softwares and processes that run on your system: calculator, for example, may be a single process running on your PC
(or laptop or mobile or tablet or supercomputer 😀), which may use the IO management and possibly some floating point arithmetic services from the OS kernel (read “services provided by OS” as “syscalls”). It is, then, counter-intuitive to allow such a program network access (like listen(), connect() syscalls).
The Problem
The Linux Kernel (v5.5) at the time of its writing supported 347 system calls (services supported by the OS). With time as the complexity of applications have increased so has the need and expectation from the OS to support such application features.
".... , ≈45%/65% of all (C/C++) applications in Debian “sid” (development distribution) [86] do not make use of execve/listen in x86-64 Linux. ..."
This opens the system to attackers in a two-fold manner: first, an attacker may be able to utilize unused OS services after taking control of a vulnerable application. Secondly, after gaining such access, the attacker may try to exploit code vulnerabilities in less used (hence, less tested and less protected) kernel interfaces to escalate its own privileges.
The Solution
The paper tries to diminish the above possibilities and make applications and the OS kernel and, hence the system overall more secure. It proposes “sysfilter”. It may be interpreted as “SYScall FILTER”. And it does exactly as the name suggests — it tries to approximate the syscalls used in (unadulterated) code and then sandboxes the application to allow only those syscalls that the developer intended to use. By doing so it not only incorporates the principle of least privilege but also reduces the “attack surface” of the OS kernel.
Sysfilter works into two cascading stages:
- syscall set extraction
- syscall set enforcement
Syscall set extraction
The extraction component receives as input the target application binary, it resolves dynamic dependencies (shared libraries) and constructs a safe but tight over-approximation of the program’s function call graph (FCG).
FCG is basically the graph of all functions in any binary (main or library) that can be invoked, arranged in a caller/callee hierarchy.
Given, the approximated FCG, FCG’, sysfilter extracts the system calls that are used/can be used in the program during any branch of execution.
To do so, sysfilter first takes as an input an (x86-64) ELF file that corresponds to the main binary of the application.
Sysfilter adds the main application binary to the analysis scope (read: list of things to be analyzed).
Then, it resolves dynamic shared library dependencies by scanning the relevant section in the application binary and getting the shared libraries that this binary requires
if you care about the details : it first reads the
PT_INTERPheader to get the .so file paths of the linker, then iterates over the.dynamicELF section, to find the entries in the DT_NEEDED; each correspond to a shared library (pheww)
whose object file is then added to the analysis scope.
Now the above steps are repeated for each of the newly added object files by scanning their .dynamic entries and recursively repeating until all dependencies are fully resolved.
Equipped with the full analysis scope, sysfilter proceeds to disassemble the binaries to extract functions. Normally this task would be undecidable but thanks to modern GCC and LLVM compilers that
- separate code and data, and
- embed stack unwinding information in
.eh_framesections.
Once a precise disassembly is obtained with all functions and their boundaries, we begin incrementally building the FCG.
-
Step 1 : [
DCG] : Direct Call Graph consists of functions that are directly invoked. For every object(ELF) file (or shared object file for shared libs), the function that is the entry point is added to the graph, along with functions that are stored in.preinit_array,.init_array,.fini_arrayand.init&.finisections of the ELF.- Then each of the functions added above is scanned for the call instructions. The target functions of such call instructions are also added to the
DCG. - The process is recursively repeated for all newly added functions.
- Thus,
DCGcontains all functions that are either entry or initialization or finalization functions or those that are directly-reachable from the above.
- Then each of the functions added above is scanned for the call instructions. The target functions of such call instructions are also added to the
-
Step 2 : [
ACG] :DCGdoes not consist of functions that are not directly called but usually dereferenced from function pointers or dynamically dispatched(C++ virtual overloads for example). Indirect call/jmp’s are hard to resolve and hence, we over-approximate theFCGby constructing theACG(address taken call graph).ACGis complete; in the sense that it would never skip any function that could be executed under any arbitrary possible input.- The process to construct the
ACGbegins by finding out all the functions whose addresses occur in rvalue expressions, function arguments, initializers or functions that correspond to virtual methods. Let this set be AT(address taken set).ATis always a superset of all possible targets of any indirect call/jmp. - A nasty proof for the same may be this : for any indirect jmp to take place, the corresponding function address must be “taken” first and loaded into a register or memory location. By scanning the above specified regions of the binary, we capture all such events of “taken & loaded” addresses.
- Now for each function in the
ATset we repeat what we did earlier and add the functions that are called via call/jmp in their body. And keep on doing this recursively for each newly added function. The resultant set formed is namedACG.
- The process to construct the
Although this should be implicit at this point, but, note that sysfilter never sees the source code of the target application or the libraries. The entire analysis upto this stage and further is always done on the binary ELFs.
- Step 3 : [
VCG] Note that the finalFCGis a subset ofDCG ∪ ACG. Although this is a safe approximation it is not tight. The reason being that not allATfunctions will be taken. Thus, theACGis pruned by removing a function (and marking it unreachable) whose address is only taken within functions that are already unreachable. This further would make some other functions unreachable. This is done iteratively until no further pruning can be performed.
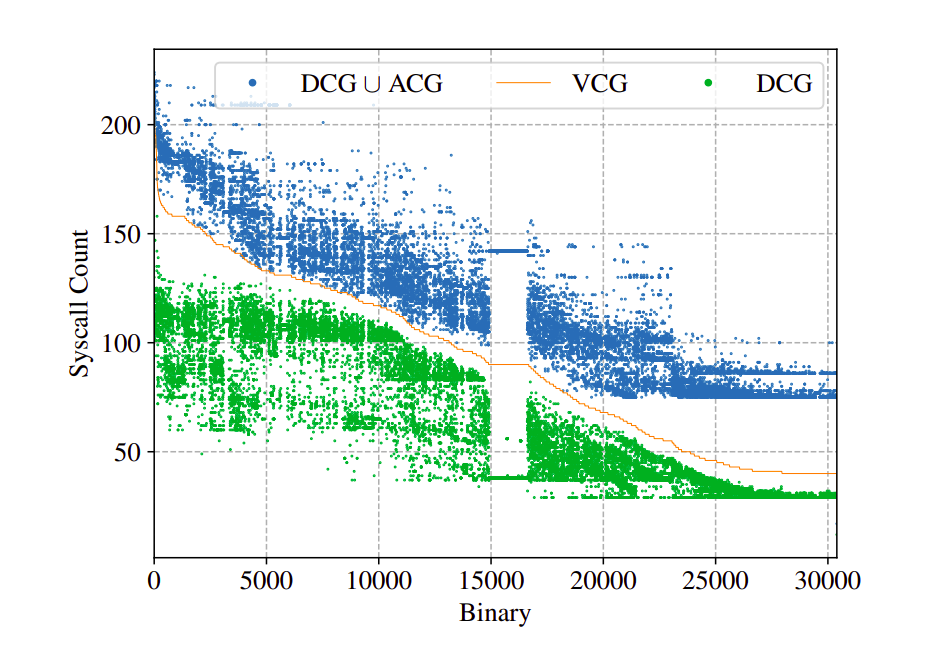
The pruned ACG, ACG' and the DCG forms the VCG that is a safe and tight approximation of the FCG.
Finally, FCG ⊆ VCG ⊆ (DCG ∪ ACG).
Now, the task of actually extracting which syscalls are used is quite straightforward. For every function in the VCG, make a linear scan over its body and find syscall instruction. From there backtrace to find the last value stored in %rax register which will be the syscall number.
Two tricky situations arise at this stage,
- One, if the value of
%raxis not constant-loaded but defined by some memory read(load) instruction then such value cannot be traced from the binary. Sysfilter may abort or continue with warnings in case such syscalls are found. - Two, the
syscall()function that allows passing the first argument as syscall number and performs indirect syscalls. If this function is not address taken then sysfilter can backtrace the last stored value in%rdiregister to find the syscall number otherwise sysfilter may abort or flag a warning.
In cases where sysfilter aborts or issues warning the resulting syscall set may be incomplete.
Otherwise,
We have a shining set of developer-intended syscalls that are to be used by the program during its execution under any possible input.
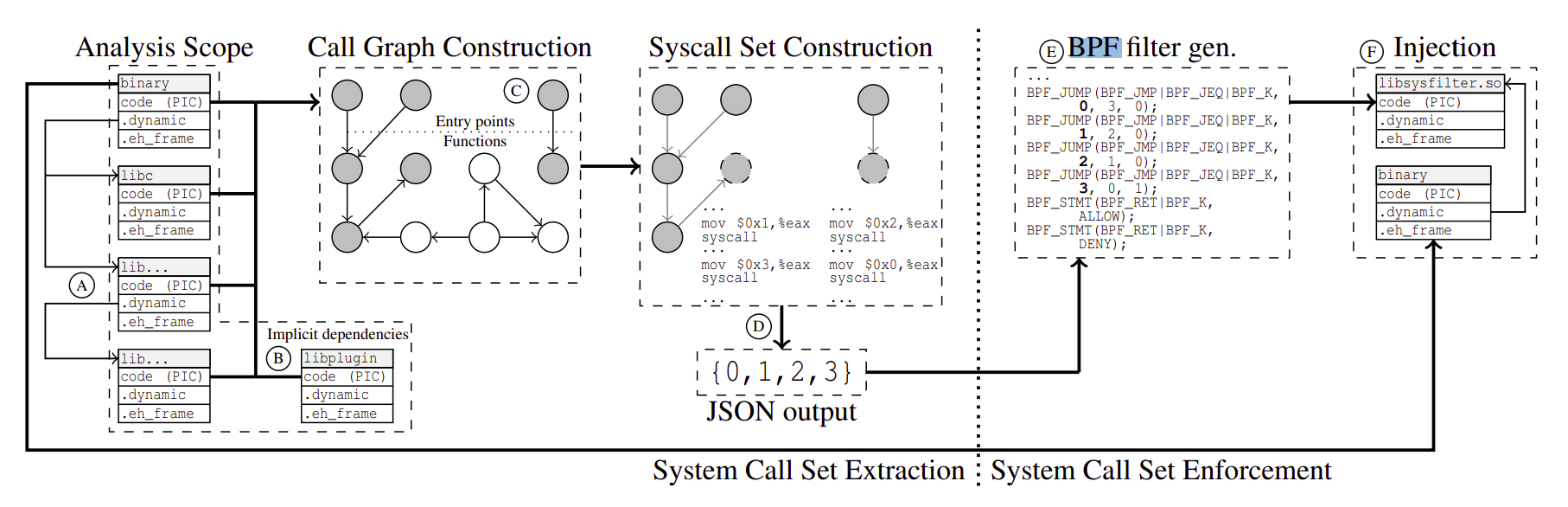
Syscall set enforcement
To enforce the extracted syscall set on program at runtime, sysfilter uses the seccomp-BPF toolkit.
Seccomp was introduced in kernel version 2.6.18 to limit the number of syscalls available to userland processes. Essentially, seccomp is meant to allow CPU share and securely renting out idle CPU cycles to foreign programs and allows only four syscalls read, write, _exit, sigreturn.
Seccomp-BPF added more flexibility to the seccomp framework. It uses BPF programs as filters to make runtime decisions. BPF (Berkeley Packet Filters) programs are written in a limited set of instructions that enable the restriction of syscalls and their arguments.
Read more here.
Sysfilter compiles a BPF program containing the restricted set of syscalls from the extracted set. This may either be in the form of a linear or skip-list based search. This filter is then jointly installed with the main binary using seccomp utilities.
To be more precise, a new binary
libsysfilter.sois generated andpatchelf()'ed to the main binary. This new binary object has only one constructor functioninstall_filterthat is automatically invoked whenld.soruns at load-time.
Now, the program can only execute the syscalls that are allowed by the filter.
There is a very interesting catch here. Think for a few seconds if you can see what it is.
....3
...2
..1
What about execve()?
If some user process running in seccomp mode issues an execve() call then would all the existing restrictions be removed. To prevent this privilege escalation, we set a no_new_privs option via the prctl(). This guarantees that filters are “pinned” to the process during its lifetime.
In such a case, if a program with execve enabled execs a new program that has a larger set of allowed syscalls, the filter would still not extend the permissions and the exec’d program has to run on the limited set of its predecessor.
Moreover, the seccomp-BPF framework is stackable, that is, if multiple filters are injected the kernel always chooses the most restrictive filter.
So, what do we have to forget about execve() ?
No. sysfilter supports two modes: union and hierarchical for execve.
In general, we supply a group of programs that may execve() each other. Then sysfilter can do one of the following two:
- take a union of the syscall sets of all the programs and then set a common filter based on the union set, or,
- start with a large set but upon execve’ing the syscall set is reduced to fit the program being
exec’ed.
The paper also supports putting a special recipe for exec to inform sysfilter to treat execve()’s accordingly.
Protection done. Speed where?
The syscall mechanism is already latency-heavy. Adding one more programming construct in the syscall path would make it even worse.
Sysfilter was tested for correctness on commodity softwares such as Nginx, Redis, SQLite, Vim, GNU Core., GNU M4, and a few more. On all the binaries, it was correctly able to estimate a safe and tight approximation of the syscall set.
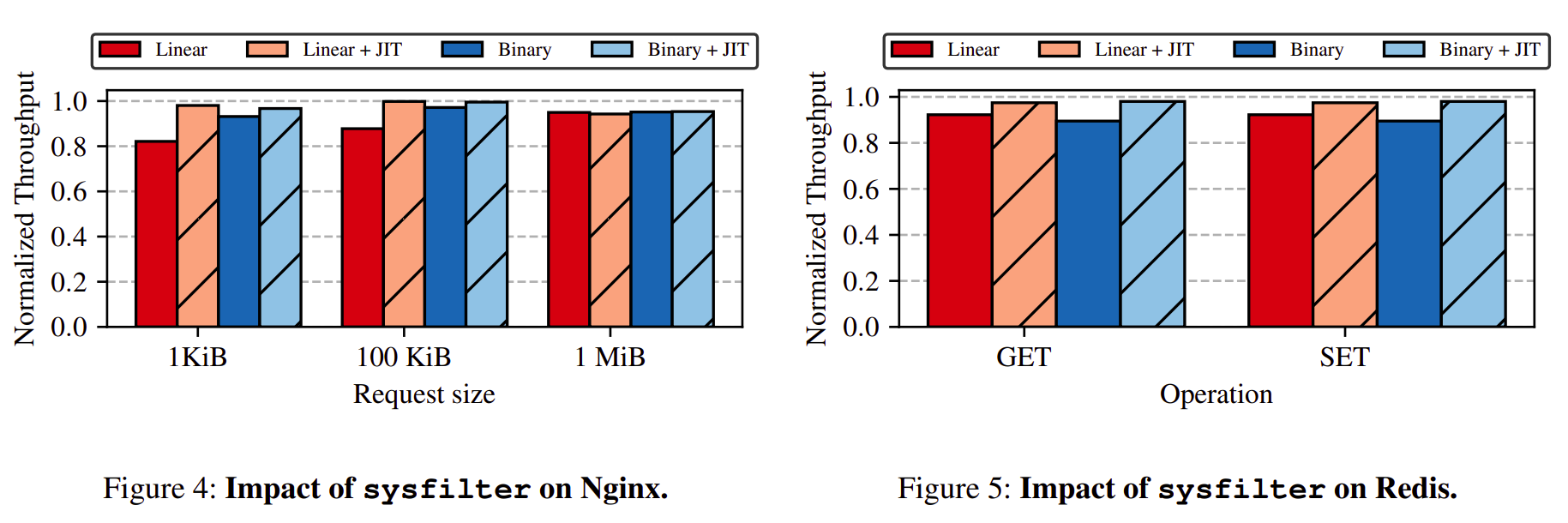
Of these, performance was analyzed on 19 performance-sensitive binaries in Nginx and Redis.The relative overhead (normalized) under 4 different settings for sysfilter: interpreted vs JIT-compiled BPF filters, and linear (“Linear”) vs skip-list(“Binary”) filter search.
A quick summary of results:
- In Nginx, without JIT compilation, linear and skip-list search result in 18% and 7% reduction in throughput.
- With JIT compilation, a maximum throughput drop of 6% is observed in Nginx.
- In Redis, a maximum throughput drop of 11% and 3% is observed with and without JIT compilation.
Well, is the performance drop worth it?
We survey the before and after of applying sysfilter to all C/C++ applications in Debian sid distribution (~30K main binaries), for 23 known vulnerabilities in kernel syscalls.
Depending on the exact vulnerabilities,
the percentage of binaries that can still attack, after sysfilter-ing, range from 0.09% (memory disclosure by adjtimex()) to 64.34% (memory disclosure by clone(), unshare()).
So, yes, removing absolutely unused syscalls has the potential to reduce the attack surface by quite a lot.
Further
Although the paper tries to address the long ignored (and already extinct) wooly mammoth (a fully open syscall API?) in the room I feel that the syscall API can be divided into sensitive syscalls and essential syscalls. Essential syscalls are the ones that are widely used, well tested, vulnerability free and hence should be fully open to all programs. The sensitive syscalls (I thus name thee, exprivcalls or extra-privileged calls) like adjtimex and others may be always restricted unless otherwise passed by sysfilter.
This would remove the latency from the heavily used API (Amdahl’s Law 🤓)
And protect the more sensitive exprivcalls from illegal exploitation.
Two roads diverged in a yellow wood
For those of you who think I have rambled on for long, I will humbly conclude now.
Aaaand,
For those that think they are worthy 🙂 scroll down below the conclusion for some interesting know-chos (knowledge-nachos) arising from the offshoots of this paper.
Conclusion
The sysfilter is a static analysis framework that tries to prevent attacks through kernel syscall interface by incorporating the principle of least privilege and reducing the attack surface of the kernel. The results do support the concern that limiting the unused syscall leads to lesser chances of attack and better protection and better sleep for system developers. Wait no, they don’t sleep 🥲.
Know-chos
- Do you know the average number of syscalls in a C/C++ program?
The paper extensively analyzed the binaries from the Debian repositories
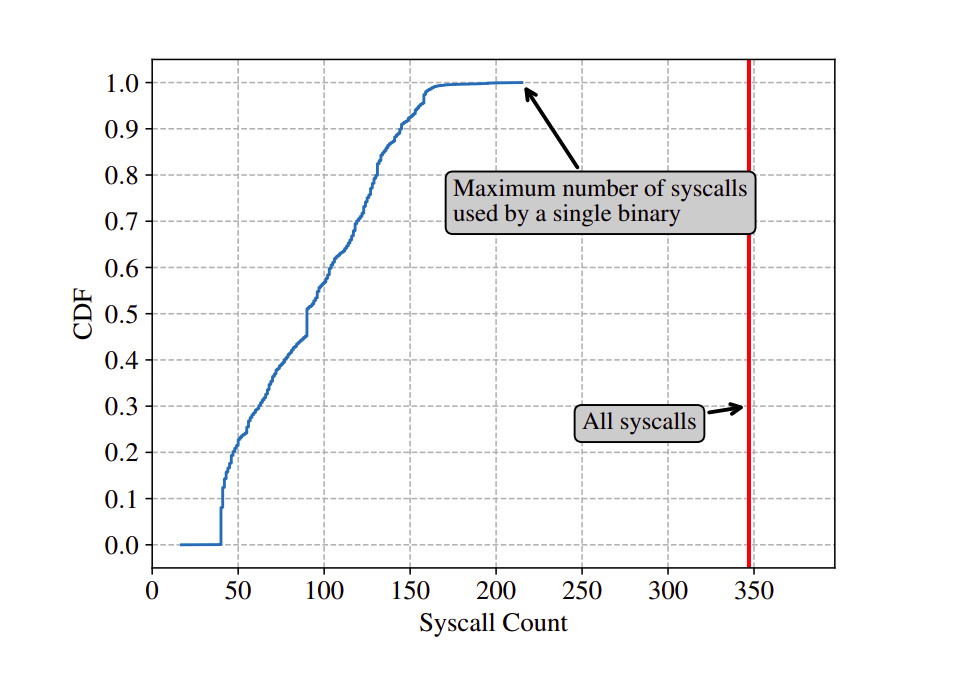
main,nonfreeandcontrib, totalling to around ~33.8K binaries.Out of 347 total syscalls, the maximum number of syscalls used by one binary is 215.
The median syscall count per binary is 90; the 90th percentile is at 145 syscalls.
All binaries analyzed except
mtcp_restart(uses only 17 syscalls) uses atleast 40 syscalls.
- How do libraries handle syscalls ?
We record which of the shared libraries contained atleast one syscall for each invocation.
After
libc, the second most common library islibpthread(used by 68.7% of the binaries) which has 40 syscall instructions. This is becauseglibcinvokes syscalls directly without using wrappers.Libraries tend to directly invoke syscalls without any
libcwrapper.libstdc++(37% of binaries) invokesfutex()directly;libnss_resolve(32% of binaries, 3 syscalls);libglib-2.0(17%, 5 syscalls)Many libraries also invoke function specific syscalls directly, most likely because of the non-existent or unavailable wrappers. Like
libcryptandlibcryptodirectly invokegetrandom,keyctl.
- Interesting visual about DCG, ACG and the VCG.
Policy-Sys: Automated Policy Synthesis for System Call Sandboxing
System call whitelisting is a powerful sandboxing approach that can significantly reduce the capabilities of an attacker if an application is compromised. While this mechanism greatly reduces the attack surface of a system, manually constructing these policies is time-consuming and error-prone. Motivated by this challenging problem, the authors of the paper (link to paper here) came up with a technique for automatically constructing system call whitelisting policies for a given application and policy DSL.

But what is this so called 'Sandbox' ?
Simply put, a sandbox is a security mechanism that separates applications from the rest of the system and prevents vulnerabilities in one component from compromising others.
One common approach of implementing such a sandboxing mechanism is to what system calls a program can make. Given a policy that specifies which system calls can be invoked with what arguments, a sandboxing framework terminates any execution that violates the given policy.
Why is it difficult to write a sandboxing policy ?

Fun Fact: Out of the top 1000 debian packages, only 6 used a syscall sandbox.
Despite their effectiveness, programmers rarely write a syscall sandboxing policies because manually constructing these policies is difficult as well as error prone. The reason why these challenges are difficult to overcome are-
-
First, in order to write a useful policy, the developer needs to identify all the syscalls (and their argument values) that could be invoked by the program including code in third party libraries.
-
Second, building a sandbox is not a one-time effort, as the policy may need to be updated whenever the application is modified.
-
Third, different operating systems expose different policy languages that vary greatly in both syntax and semantics, making it especially difficult for cross-platform applications to build and maintain their sandboxes.
-
Finally, since sandboxes are constructed manually, they inevitably contain bugs and may end up terminating legitimate executions of a program.
The task
Cited formal problem statement- "Given a program 𝑃 and a sandboxing policy language 𝐿, the authors wish to design a technique that automatically constructs a policy 𝜓 in 𝐿 that over-approximates the necessary syscall behavior in 𝑃 as tightly as possible. At a high-level, the approach consists of two phases, namely, syscall analysis and policy synthesis. In the first syscall analysis phase, the authors perform abstract interpretation on 𝑃 to compute a so-called syscall invariant Φ that over-approximates syscall usage patterns of 𝑃 for well-defined executions. However, since this syscall invariant is, in general, not expressible in the given policy language 𝐿, the goal of the second policy synthesis phase is to find a best policy in 𝐿 that over-approximates 𝑃 as tightly as possible. Since the synthesizer is parametrized by a policy language 𝐿, this approach made it possible to generate policies for multiple syscall sandboxing environments with different policy languages."
The Sycall Analysis Phase
The goal of the syscall analysis phase is to compute the set of system calls the program can invoke, along with predicates that constrain their argument values. Observations which affect the choice of design pattern are-
-
Integer-valued syscall arguments often serve as important flags and crucially affect policy choice.
-
observed that argument values of syscalls are often independent of one another.
-
It is important for the analysis to support some type of disjunctive reasoning.
-
There are many cases where important syscall arguments depend on values of array elements.
-
Since most syscalls are invoked in library functions with complex implementations, it is crucial for the analysis to be both interprocedural and scalable.
Policy Synthesis Phase
Informally we can understand this phase as- Given the syscall usage information produced by the static analysis phase, the goal of the policy synthesis phase is to construct a sandboxing policy that over-approximates this information tightly .
Formally the paper states the problem statement of this phase as- "The synthesis algorithm takes as input a policy DSL 𝐿 and a syscall invariant Φ which summarizes the program’s syscall usage (e.g., information from Table 2) as a logical formula. Then, the goal of the synthesizer is to generate a program 𝜓 in 𝐿 such that Φ ⇒ ⟦𝜓⟧ is valid (i.e., 𝜓 should allow all resources required by the program). Furthermore, since we want to find tightest policy expressible in 𝐿, the synthesis output should guarantee that 𝜓 is not weaker than any other policy 𝜓 ′ satisfying Φ ⇒ ⟦𝜓 ′⟧."
ABHAYA comes to the rescue!
The authors designed ABHAYA, a top-down summary-based interprocedural static analysis that focuses on tracking values of integer-typed variables and single-level arrays to automate policy synthesis adhering to the the observations made in Syscall Analysis and Policy Synthesis phase.
Before moving on to the policy synthesis algorithms it is important to get a brief idea of the following terms-
Please Note- this is a brief overview of the terms required to understand the implementation of ABHAYA. The detailed mathematical formulations have been skipped in the interest of simplicity and time.
-
Summary: Each summary maps the initial abstraction on function entry to the resulting abstraction after analyzing the function body.
-
Syscall Invariants: Simply put a syscall invariant maps each system call invoked by the application to a formula describing possible values of its arguments.
-
Feasible Syscall states: Feasible syscall states characterize all legitimate syscall usage patterns of a given program.
-
Sound Policy: We say that a policy is sound with respect to a program P if it accounts for all feasible syscalls of P.
-
Complete Policy: We say that a policy is complete with respect to a program P if the policy accounts for only the feasible syscall states of P.
Fun Fact: In general, it is not possible to write policies that are both sound and complete.
-
Intraprocedural/Interprocdural Transformers: These are a set of rules which describe a simple imperative language comprising statements which include standard constructs like assignments, loads, stores, conditionals, and memory allocation.
Interestingly we can omit pointers and structs as they are modeled as arrays. We can also omit loops because they can be emulated using tail-recursion.


Since these transformer rules are especially mathematics intensive, I advise the reader to go through the paper for this section.
Syscall Analysis Algorithm

The Analyze(P) procedure generates set of syscall formulas named γ. Using soundness property of policy we can say that γ is syscall invariant of P.
The algorithm iteratively analyzes each entry from the worklist(a set of summaries that need to be analyzed) using the subroutine analyze. The analyze subroutine produces syscall invariant for each entry of the worklist. Any change in context of the worklist, including all changed summaries and their dependencies, need to be re-analyzed and are therefore added back to the worklist.
Optimal Policy Synthesis Algorithm

The Synthesize procedure takes as input a syscall invariant γ and policy language 𝐿, and returns a policy Ψ.
Lets go through the steps of the algorithm one by one-
-
The algorithm performs a top-down search over policy templates, which are policies with unknown groups (denoted ? 𝑔 ), unknown predicates (denoted ? 𝑏 ), or unknown (integer) constants (indicated as ? 𝑐 )
-
worklist 𝑊, initially contains guarded syscalls of the form (𝑓𝑖 , ? 𝑏 𝑖 ) as well as 𝑘 groups ? 𝑔 1 , ··, ? 𝑔 𝑘 for each possible value of 𝑘.
-
The main loop expands the worklist 𝑊 and populates set Π until 𝑊 becomes empty, at which point Π is guaranteed to contain all optimal policies
-
For each template we have the following possibilities which are handled accordingly- No unknowns, Unknown groups and Unknown predicate
-
At the end of the main loop, Π is guaranteed to contain all optimal policies; thus, th algorithm selects one optimal policy and returns it as the solution.

Please refer to the paper to gain insight on the process/algorithm of solving policy templates. It is quite complicated and frankly I too do not clearly understand all the intricacies mentioned in the paper.
Results

We can judge the performance of ABHAYA by discussing few simple questions-
-
QUESTION: Can Abhaya’s policies block real-world exploits?
RESULT: 96% of the Abhaya-sandboxed applications are resistant to > 95% of known privilege escalation attacks.

-
QUESTION: How do Abhaya’s policies compare with manual ones?
RESULT: Abhaya’s policies match manually-written policies with an average F1-score of 0.94 and exactly match the manual policy for the majority of the benchmarks.

-
QUESTION: How long does Abhaya take to generate policies?
RESULT: Abhaya can synthesize policies for applications with >100K LoC(LLVM code) within a few minutes on average.(Refer to figure)
Automated Response Using System-Call Delays
The first thing that might come to your mind is What is "Automated Response"? Let us familiarize ourselves with that first. In the domain of computer security, a challenging task is to identify any anomaly and take appropriate action against the detected intrusion. So, computers must respond to attacks autonomously for maintaining their integrity(i.e to stay uncompromised).
As it turns out, one form of automatic response to adversities is already present in living beings. Can you guess what it is?
If you want a hint, I would ask you to think about a specific mechanism that you might have studied in biology.
If you guessed homeostasis, you are right!
Introduction to pH
Well, in biological terms, maintaining a stable internal system is known as homeostasis. All living systems apply this mechanism to respond to various internal environmental conditions. Based on this idea, the authors have proposed a novel mechanism called "pH" (process homeostasis) for monitoring, detection, and prevention of attacks on a system.
Why pH?
Previously, commercial intrusion detection systems were able to generate some forms of response but were challenging to implement in practice due to the risk of having inappropriate responses and the system becoming inconsistent. This in turn could lead to an increased workload on system admins. So, the requirement for a fast,reliable autonomous intrusion response system led to the invention of pH.
Now, let us understand how pH was designed and implemented to serve its purpose.
Design and Implementation of pH
pH mainly achieves two major functionalities:
- It monitors every system call in real-time without much impact on overall system performance.
- It responds to anomalous system behavior which was difficult to implement earlier in practical scenarios.
Let us understand how pH performs its objectives i.e syscall monitoring, anomaly detection, and response generation.
Syscall Monitoring
-
Every time a process starts executing, pH logs all syscalls for that process, and a
traceof syscalls for that process is generated. Heretraceof a process refers to a time series of the syscalls made by that process. -
Commonly executed programs especially programs that run with privileged mode are invoked several times and their traces are collected to develop an empirical model of the normal behavior of such processes.
-
Finally, the collection of such syscall traces is passed in a sliding window and the "normal behavior" of a program is defined as a short n-gram of syscalls over the current window.
For example, if a program makes the following syscalls:
execve, brk, open, fstat, mmap, close, open, mmap, munmap
Then for a sliding window of length 4, the following table is generated as a normal profile of the program.
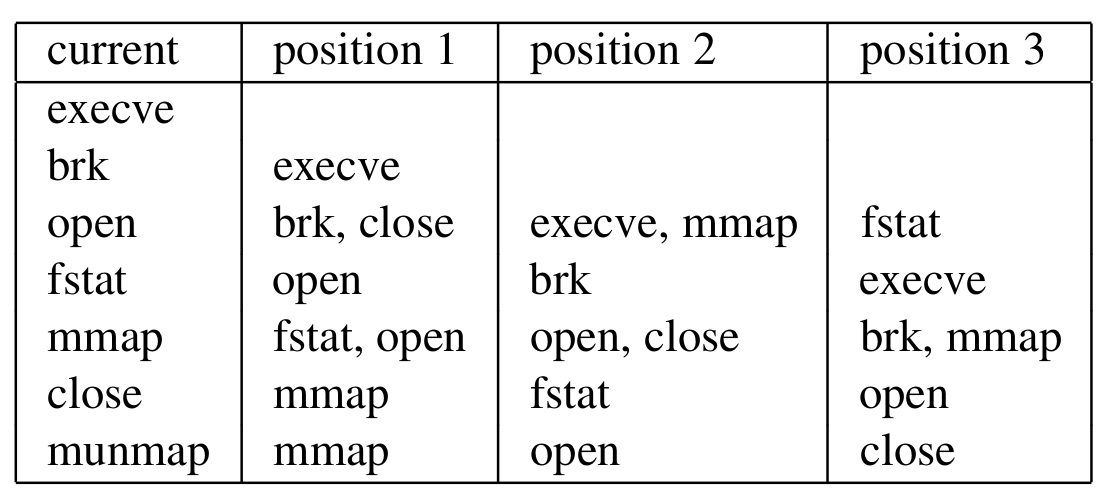
Note that the table shown above is a compact representation of multiple rows merged into one wherever possible.(position[i] denotes the i-th syscall made before the current one).
During implementation, this table is stored as an S x S x (w - 1) byte array (where S is the total number of system calls possible, and w denotes the window size). For each row, any two syscalls from two different columns form a "pair" and such pairs construct the normal profile of a program.
Now, let us move forward to see how the above traces help us to detect anomaly in an executing process.
Anomaly Detection
-
During the execution of a process, for a current syscall, if there is a pair in its current profile which is not present in the normal profile, then it is defined as an anomalous syscall.
-
Here, the authors define a metric
'LFC'(Locality Frame Count). It implicitly stores the number of the past n system calls which were anomalous (n is a predefined parameter). This is defined as the'total of recent anomalies'. In this way, the system is able to detect the anomalies occurring on a per-process basis as well as the locality count of such anomalies.
Now we are going to look into the most interesting part of this paper.
Automatic Response Generation
Feel free to pause here to think yourself what could be the ideal response to an anomalous process.
You might have already guessed it from the title of the paper.
The idea is to delay the execution of anomalous syscalls. Whenever an anomalous syscall is detected, there are two possible scenarios:
- It is indeed an anomaly and it might compromise the system i.e a true positive.
- It might be a false positive simply because we had never seen such a sequence in the normal profile of the program.
Hence, delaying every syscall from the beginning might lead to unstable state of the host system. Then how do we decide when to start generating responses to anomalies?
Here, a formal response mechanism using special mathematical heuristics was developed along with some control parameters to control the behaviour of pH. I won’t dig deep into the exact nitty-gritty details. You can always refer to it in the paper itself. However, here is a quick summary of the mechanism:
-
For each running executable, pH maintains two byte arrays of pairs of data (as discussed during syscall monitoring) - training array and testing array.
-
The training array is continuously updated as new sequences appear during the execution and the testing array is used to detect anomalies. For simplicity, assume that testing array stores the current normal profile of a program and when in doubt of an anomaly, the system compares the syscalls with the profile present in the testing array.
-
The testing array is never modified manually. However, it is replaced by the training array under some special circumstances. This is known as "installing a new normal" for the process. The replacement occurs under the following 3 conditions:
- Whenever a user explicitly declares using a special syscall (
sys_pH) that the current profile in the training array is valid. - When the current profile exceeds a control parameter called
'anomaly_limit'predefined by pH. - When the training formula is satisfied. Now, this formula has several layers inside it. Just for simplicity, you can assume that whenever some conditions set by pH satisfy, it is inferred that the normal profile of a process is successfully trained and can be used further for anomaly detection. Hence, it is copied into the testing array.
- Whenever a user explicitly declares using a special syscall (
Now, whenever an anomaly is detected, pH effectively delays the syscall by a factor of d = 2LFC and using a control parameter 'delay_factor' the effective delay obtained is = d x delay_factor. Now, there are other types of responses implemented in pH to handle several edge cases. For example, if the maximum count of LFC for an executing process exceeds a certain threshold, all execve calls are aborted so that pH does not get tricked into treating the current process as normal based on the data of the newly loaded executable.
Implementation wise, the pH prototype was developed as a patch for Linux 2.2 kernel. Moreover, the authors extended the Linux Task data structure to store the following fields for each process:
- The current window of syscalls
- Locality Frame
- Profile of the task - which contains two byte arrays for training and testing along with some additional data.
The system call dispatcher was modified such that it calls a pH function(pH_process_syscall) before dispatching the syscall. This allows pH to start monitoring and give response. To control pH, the special syscall sys_pH allows the superuser to manually signal the system to set pH control parameters, start/stop logging and do several other operations to control pH. Finally, the overall flow of control and data after the addition of pH looks like this:
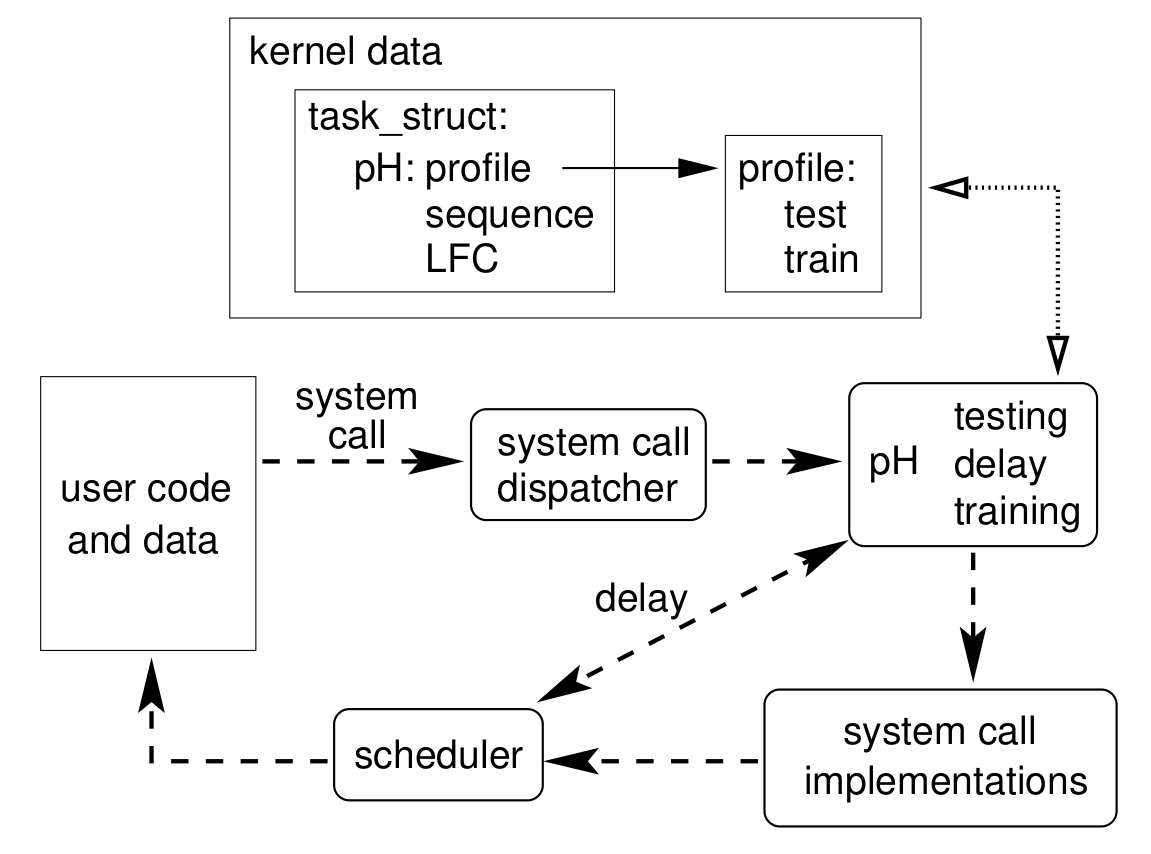
pH in Action
After the authors installed pH into their system, they used a few vulnerabilities of Linux Kernel from the official mailing groups and tried to handcraft several attacks themselves. The response generated against one such event is shown below.
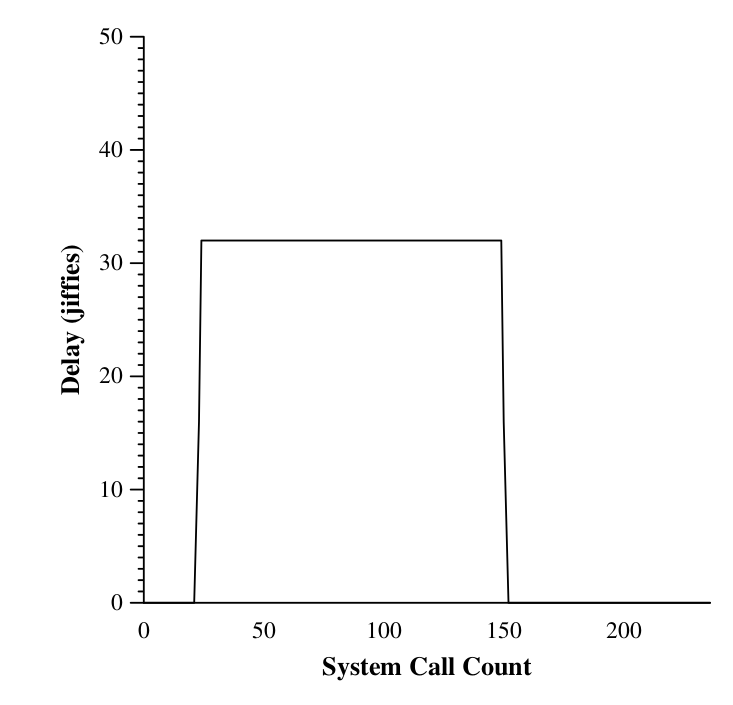
This is a graph showing the pH-induced system-call delay during the sshd backdoor intrusion. Note the exponential increase (from 0 to 8, 16, then 32) and decrease, with a constant delay for most calls within the locality frame. The system was able to delay the resulting connection significantly to make the cracker possibly think that the attack is not working. It was also feasible to close the backdoor when the flag 'abort_execve' was enabled.
The response generation is fine! But do you think there is any effect on the system due to addition of pH?
Installation of pH comes with additional latency for running each process and making syscalls. Check the following table to understand it. (Standard deviations over 10 runs are listed in parentheses).
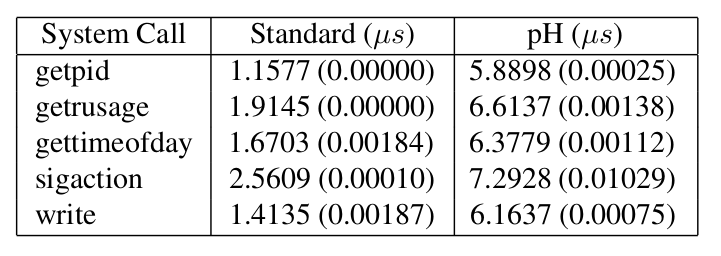
However, the overheads are nearly imperceptible to a normal user.
Merits
-
The most interesting fact that we found out in the paper is that the authors have proved that with minimal overhead, it is possible to do real-time monitoring on every syscall occurring on the system by tweaking the kernel task data structure.
-
Also, the fact that delaying a syscall can confuse an attacker is quite cool and might lead him/her to voluntarily give up. Even if that is not the case, the authors have also addressed methods to stop the attack by terminating the process intelligently.
Demerits
-
According to me, the behavior of pH does not generalize well. The authors have shown how it behaves differently under different control parameters which were set manually but it does not provide a universal way to automatically learn those parameters for each type of attack or event. At least some human supervision is anyways required for its controlled management. So it is not fully automatic.
-
Although it generally performs well on a single-user system, there is no proof or disproof whether a multi-user system will be stable upon the activation of pH where users may have different roles and multiple users may have root access and might try to control pH. There is a need to address these scenarios because in such cases, pH itself might be vulnerable to attacks.
FlexSC: Flexible System Call Scheduling with Exception-Less System Calls
System calls are the de facto interface to the operating system kernel. They are used to request services offered by, and implemented in the operating system kernel. They have been universally implemented as a synchronous mechanism.
The paper shows that synchronous system calls negatively affect performance significantly and proposes a new mechanism for applications to request services from the kernel: exception-less system calls.
First we are going to discuss the performance issues associated with the synchronous system call implementation and then we will explore the solution proposed in this paper, that is, FlexSC.
The Problem
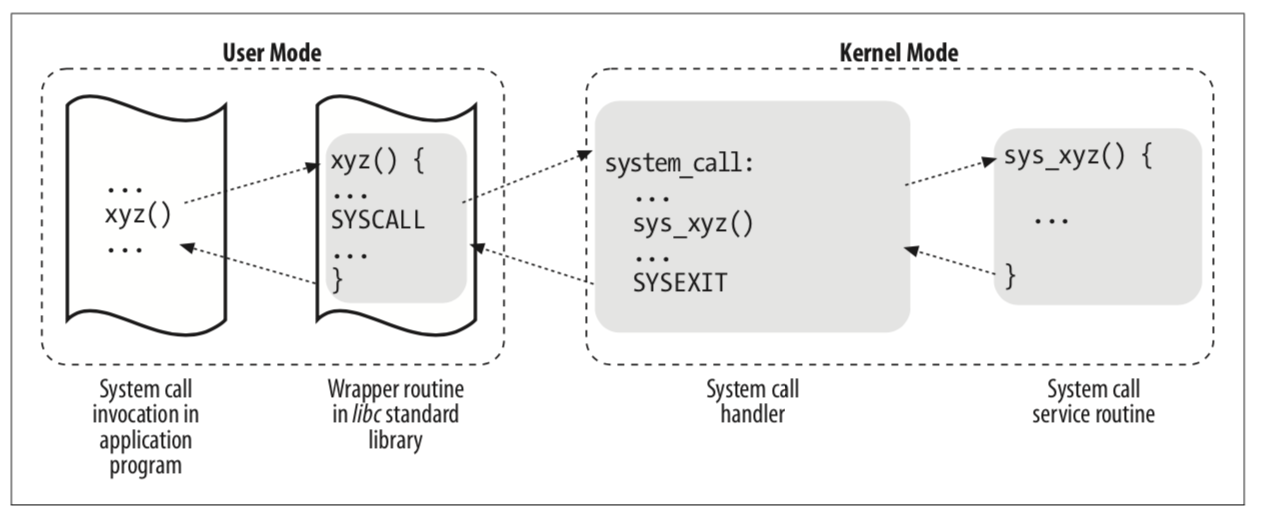
System call invocation typically involves writing arguments to appropriate registers and then issuing a special machine instruction that raises a synchronous exception, immediately yielding user-mode execution to a kernel-mode exception handler.
The two important properties of the traditional system call design are that:
-
A processor exception is used to communicate with the kernel
-
A synchronous execution model is enforced, that is, further execution of the user program is blocked until the completion of the system call
But both of these properties result in performance inefficiencies. The negative impact in the performance of system-intensive workloads is observed both in terms of direct costs of mode switching and indirect pollution of important processor structures which affects both usermode and kernel-mode performance.
- Mode Switch Cost
Execution of system calls involves execution in an elevated protection domain (kernel mode), and the return of control back to user mode.
Modern processors implement the mode switch as processor exception which involves several steps: flushing the user-mode pipeline, saving registers onto the kernel stack, changing the protection domain, and redirecting execution to the registered exception handler.
Well, this takes a lot of time!
The authors identified the total number of cycles necessary to enter(79 cycles) and leave(71 cycles) the operating system kernel.
- Indirect cost of pollution of important processor structures
When user-mode switches to kernel mode, processor structures including the L1 data and instruction caches, translation look-aside buffers (TLB), branch prediction tables, prefetch buffers, as well as larger unified caches (L2 and L3), are populated with kernel specific state.
The replacement of user-mode processor state by kernel-mode processor state is referred to as the processor state pollution caused by a system call. This has affects on both User IPC and Kernel IPC.
Quantitative analysis of the impact caused
Ultimately, the most important measure of the real cost of system calls is the performance impact on the application.
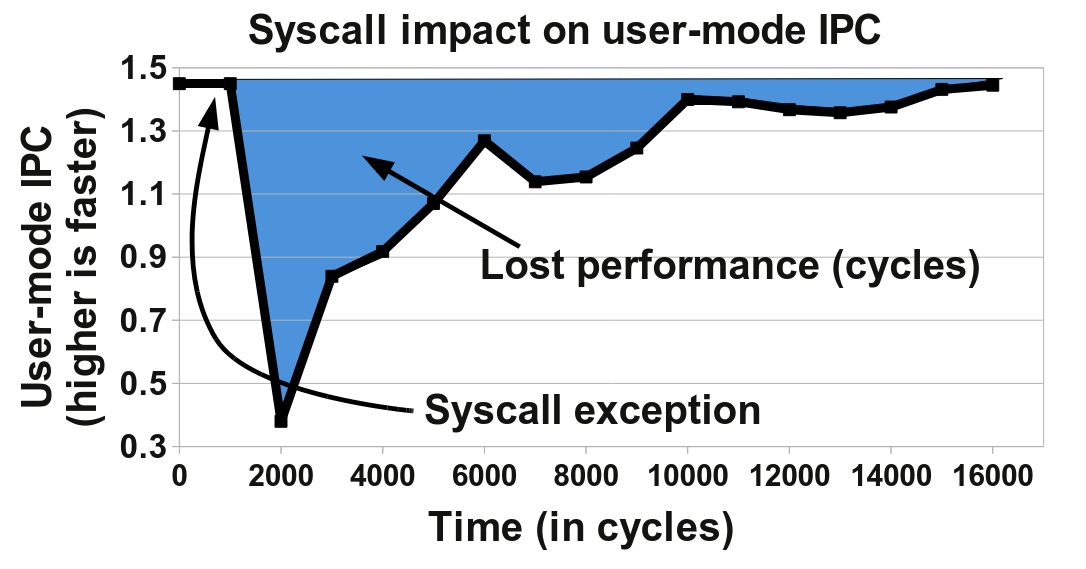
The figure below depicts the user-mode instructions per cycles before and after a pwrite system call. There is a significant drop in instructions per cycle (IPC) due to the system call, and it takes up to 14,000 cycles of execution before the IPC of this application returns to its previous level.
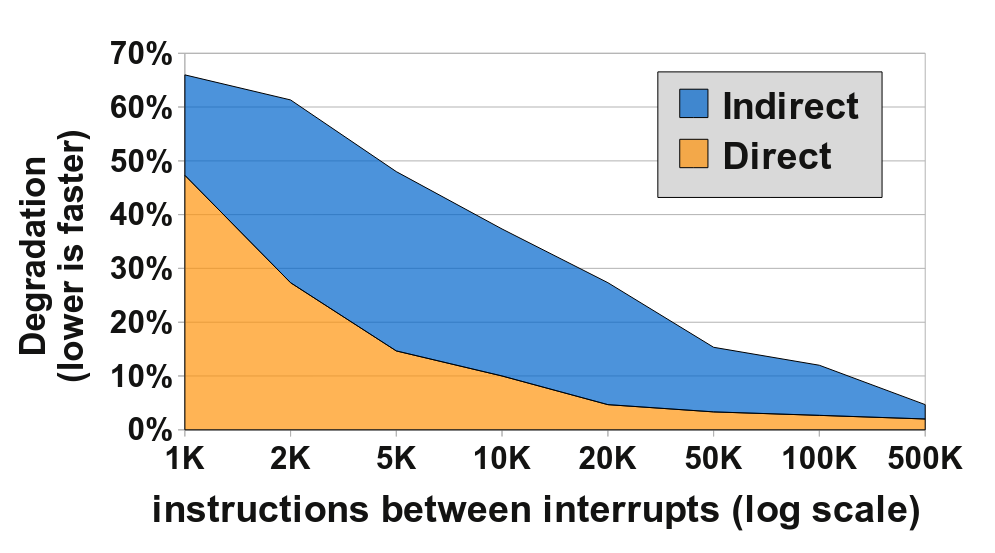
The figure below shows the degradation in user mode IPC given different frequencies of pwrite calls
The Proposed Solution
Now, we will discuss about the second part of the paper where the authors propose exception-less system calls to address (and partially eliminate) the performance impact of traditional, synchronous system calls on system intensive workload.
Syscall Pages: The Interface
Syscall pages are the interface for exception-less system calls, they are simply a set of memory pages that is shared amongst user and kernel space. They are organized to contain the exception-less system call entries. Each entry contains space for the request status, system call number, arguments, and return value.
Invoking system calls
To issue an exception-less system call, the user-space threads does the following
-
Find an entry in one of its syscall pages that contain a free status field.
-
Write the syscall number and arguments to the entry.
-
The status field is then changed to submitted, which indicates to the kernel that the request is ready to be executed
The thread must then check the status of the entry until it becomes done, consume the return value, and finally set the status of the entry to free.
Syscall Threads: Decoupling invocation and execution
In exception-less interface, the system call is implemented separately from the execution and it does not result in an explicit kernel notification, nor does it provide an execution stack. To support decoupled system call execution, a special type of kernel thread called syscall thread are used. Syscall threads always execute in kernel mode, and their sole purpose is to pull requests from syscall pages and execute them on behalf of the user-space thread.
How does it improve performace?
-
Multiple system calls can be collected and executed together in order to achieve temporal locality.
-
These syscall threads can be scheduled on a different processor core than that of the user-space thread, allowing for spatial locality of execution.
The above factors lead to improved performance over the synchronous implementation,
Execution of System calls and Thread Scheduler
FlexSC spawns as many syscall threads as there are entries available in the syscall pages mapped in the process. This is for that worst case where every system calls blocks during execution. Spawning so many threads may seem expensive, but Linux in-kernel threads are typically much lighter weight because they only need task struct and a small stack.
Despite spawning multiple threads, only one syscall thread is active per application and core at any given point in time.
-
The FlexSC scheduler wakes up an available syscall thread that starts executing the first system call.
-
When a syscall thread needs to block, for whatever reason, immediately before it is put to sleep, FlexSC notifies the work-queue.
-
Another thread wakes-up and immediately starts executing the next system call.
-
When resources become available, the waiting thread is woken up to complete its execution, it posts it's result to the syscall page and returns to wait in the FlexSC work-queue.
For multicore execution, the scheduler biases a few of the cores for the execution of syscall threads. In the current implementation, this is done by attempting to schedule syscall threads using a predetermined list of cores.
Their implementation improved performance of Apache by up to 116% and MySQL by up to 40% while requiring no modifications to the applications
Use case for future exploration
For event-driven systems, the author propose a hybrid approach where both synchronous and exception-less system calls coexist. System calls that are executed in performance critical paths of applications should use exception-less calls while all other calls should be synchronous. The authors did not attempt to evaluate the use of exception-less system calls in event-driven programs.
Merits
-
Their implementation decouples invocation from execution which allows for batching, that is multiple system call request could be executed together, thus reducing number of switches between user mode and kernel mode.
-
Having separate kernel threads allows for dynamic core specialisation. So, the processor structures are not polluted with data from the other mode of execution.
Both these allow for improved locality and lead to improved performance.
Demerits
I feel like their idea works well in applications which are system intensive but not time sensitive. For applications requiring immediate execution of system calls, it is not desired that the request be waiting until the batch size is large enough.
Also for systems having less number of cores and threads, the threads will get blocked and mode switch between user mode and kernel mode will be done frequently.
References
Here are the papers this blog is based off. The papers are specified in the order of their respective sections:
- Privbox: Faster System Calls Through Sandboxed Privileged Execution
- sysfilter: Automated System Call Filtering for Commodity Software
- Automated policy synthesis for system call sandboxing
- Automated Response Using System-Call Delays
- FlexSC: Flexible System Call Scheduling with Exception-Less System Calls