Yeah, we've been there and done that, thanks to Covid. Funnily enough, computers need isolation for almost the exact same reason. We want an OS to not crash even if some drivers fail (I'm looking at you Windows). We want to be able to run random thing on our machine without consequences (snake oil, but still a decent dream). We want to be able to ....
We really want isolation in our OS.

RedLeaf OS: A "safe" Ring 0 OS
Paper link here. All figures are taken from the paper.
History repeats itself - and even more so for computers it seems. Most early computers (like the PDP's and the VAX's) were weirdly trusting machines, with everything in the same ring, with no MMU, all IO was memory mapped. It was so bad that to even get a reasonable OS on such machines, you needed history's most successful hack-job, DOS, or you had to neuter the brilliant idea of Multics to make Unix (if you know, well, you know). And then over the years, we had increasingly higher amounts of hardware isolation, memory protection and lots of rings (so many that you can't actually access all of them from your OS). All modern OS's are built around these hardware protections, even creating marvellous hacks based on them (like page-faults are used for lazy page loading in Linux). It's quite clear, the OS runs in Ring 0, userspace runs in Ring 3 and you need syscalls for anything that goes from userspace to kernel-space.
Except for one genius with the name Terry Davis - for in his temple, everything runs in Ring 0, hence the name TempleOS. And after all why shouldn't they, because he wrote every last instruction that runs on his machine, from the language, to the compiler, to the OS, to its applications.
Now, maybe we don't need to go so far. Maybe there is a middle ground. Perhaps, an existing language which can be leveraged to create isolation between the random game you downloaded from FileHippo and the browser where you buy stuff off Amazon ...
Enter the Rust
If you do anything in systems, you are probably, by now, tired of Rust-evangelists proclaiming that you must embrace Rust in order to safe your rotting C codebase. I know, because I am one myself. Notwithstanding, Rust's linear type system allow for us to create safe abstractions, which can't leak memory (so long as we stick to safe Rust). Rust's trait system allows us to define interfaces, and with a bit of separate AST processing, we can make our custom IDL, which defines safe interfaces between an application and the kernel, as well as between applications.
So, let's get our hands Rusty!

You shall not pass my Domain
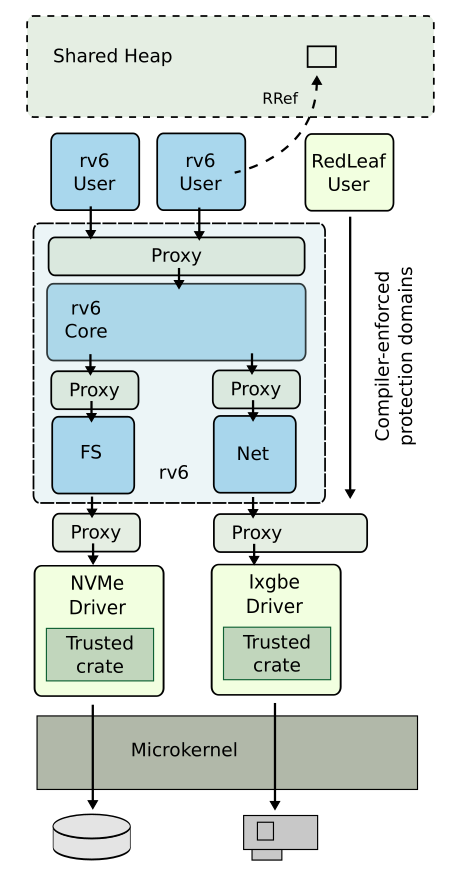
RedLeaf has a fairly simple architecture - at the bottom sits the micro-kernel, acting as the hardware overlord. Everything else is implemented as user processes (which is again typical for micro-kernel architectures). Each user process runs in its own domain.
The golden rule for domains is:
Domains cannot access each other, at all. They can only communicate via shared objects.
Moreover, domains cannot arbitrarily communicate with each other. They must do so through pre-defined interfaces, defined in an IDL, which is first checked by the kernel. This way domains simulate the same effect as user-level processes in typical OS's with user-mode/kernel-mode. Also, this makes faults between domains isolated, the same way one process crashing doesn't bring down the system (cough, Windows, cough).
Memory is the key
The primary way processes can interfere with each other or with the kernel is via memory. In regular
OS's this is protected by separating kernel memory from user memory, and using virtual addresses.
RedLeaf solves this in a different way - by giving each domain its own private heap. The stack is
anyway private to a domain. To reduce the overhead associated with maintaining a separate heap for domain,
the kernel only provides for a coarse-allocator, via its direct interface with the domain. Domains
can get fine-grained allocation via a "trusted" crate (the Rust term for a package). Memory is handed
out using Rust's Box<T> type, which is basically a pointer that frees itself.
But processes do need to communicate with each other, and even more so in a microkernel architecture.
That's where the shared heap comes to play. There is a single, large shared heap, accessible to all
domains. Allocations to this shared heap is returned as instances of the RRef<T>. This is a cross between
a Rc<T> and a Box<T>. If instances of RRef<T> are passed by reference, then the Deref impl on
RRef<T> causes its reference count to go up. However, it is to be noted that this happens only for immutable
references. Mutable references to RRef<T> is disallowed by the IDL compiler. RRef<T> values can
however be moved, passing their ownership from one domain to another.
There are some restrictions, of course, to RRef<T>. For instance, the T cannot be something that
holds a pointer to something in any heap. It can be thus something that is Copy or is itself an RRef.
The nice thing is that all these are enforced by Rust's type system (to be specific, trait bounds, using
private traits - the rest being taken care of by the orphan rule).
If we communicate, we win
(This of course is a reference to Brimstone from Valorant)
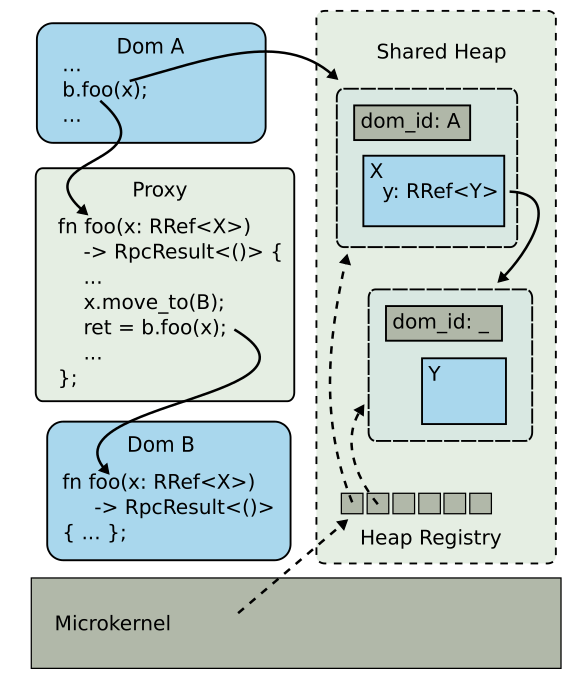
Domains communicate via something called invocation proxy. These "intercept" all cross domain
calls, causing effectively a context switch in the microkernel. These is required since domains act
like processes. Also, any data that is passed from one domain to other must be an RRef. The proxy ensures
that these RRef's when passed by value change their owner domain and increase their ref-counts when
passed by reference.
The interface is defined in an Interface-Descriptor Language (IDL). The IDL used by RedLeaf is a subset of Rust, with a bunch of attributes defined on them. This allows use of Rust's AST parsers to validate the IDL and generate bindings for the interface, which are then used by the domains themselves.
pub trait BDev {
fn read(&self, block: u32, data: RRef<[u8; BSIZE]>)
-> RpcResult<RRef<[u8; BSIZE]>>;
fn write(&self, block: u32, data: &RRef<[u8; BSIZE]>)
-> RpcResult<()>;
}
#[create]
pub trait CreateBDev {
fn create(&self, pci: Box<dyn PCI>)
-> RpcResult<(Box<dyn Domain>, Box<dyn BDev>)>
}
This IDL fragment defines the interface for a block device driver, which must implement two methods
read and write. In addition, the CreateBDev trait is marked as #[create] because that provides
the "entry" point of the domain. This is called when the domain starts executing. This is same as the
_start function which is typically the entry point for regular ELF files in Linux loaded by ld.
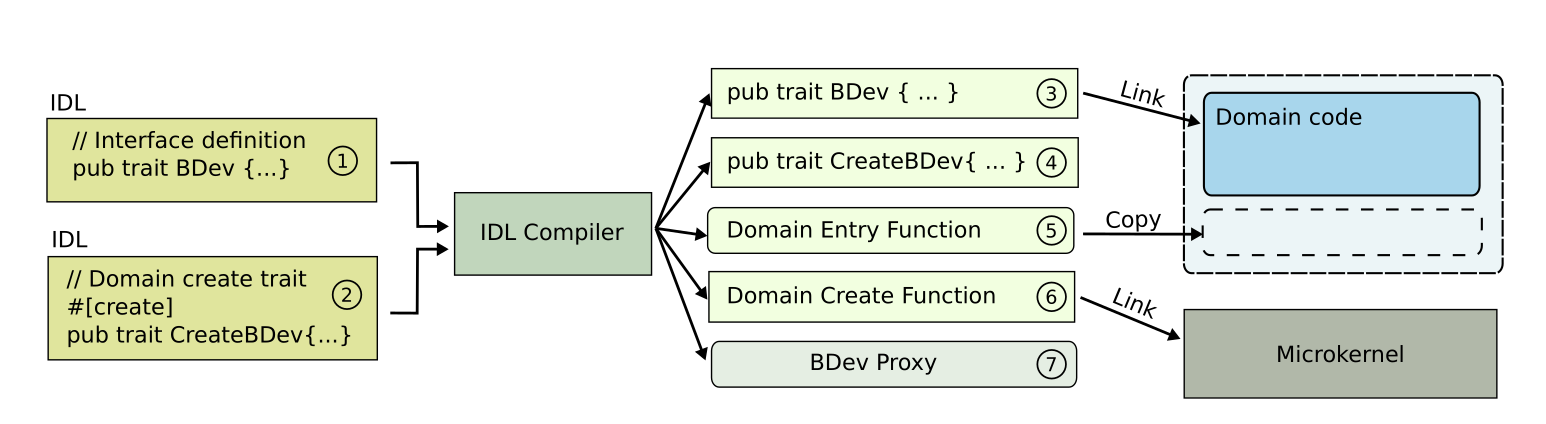
The IDL compiler takes IDL definitions such as above and creates a bunch of Rust code as well as the actual traits which can be implemented. This is shown in the figure above. In particular, it creates the invocation proxy, which gates any calls to and from this block device domain. Also, the domain entry and create functions are added onto the actual block device code.
I feel the need, the need for speed
RedLeaf is in itself a nice idea, but it'll just be an idea if it doesn't go fast enough. The key reason why microkernels are never really used in any production OS (even the ones that claim to be micro end up being not-so-micro in the end) is the cost of IPC. It is no different for RedLeaf as well.

The table above compares the number of CPU cycles spent in IPC latency. The first three utilize hardware based switching (and are all microkernels), while the rest are different cases of RedLeaf. So as it turns out, RedLeaf performs really well, beating all the hardware based solutions. This is the temple that Terry Davis had imagined! (well not quite, because Rust is heresy after all, Holy C is the real deal)
The authors go into a bunch of benchmarks after this. Many of them are out-performed by their Linux counterparts, because of the IPC overhead. But, it turns out that if we cleverly arrange the domains, then the performance is at-par with Linux, since the extra time spent for IPC is saved by the time saved by not having to change execution levels and flush the TLB.
Are the grapes sour?
The idea behind RedLeaf is not new - even if we ignore TempleOS, Google's Fuchsia already employs a similar technique for IPC and process isolation. Of course, Google being Google designed an entire new IDL, with its own compiler, IR and backend generators, just for Fuchsia. The real cool thing about RedLeaf is that it manages to do that without inventing a new language and leveraging the powers of an existing language. The use of Rust makes not only the kernel codebase safer, but also the processes safer and memory error proof. The downside is, of course, it is Rust, and so you have to write everything in Rust for it to work on RedLeaf. So it is not really a practical OS to run code on. But the idea is still applicable, and can be used in sub-systems of an OS instead of the entire OS. More over, the Ring 0 architecture itself is quite attractive as long as processes can be well isolated, which is exactly what RedLeaf does.
KVell+ : Snapshot Isolation without Snapshots
Paper link here. All figures are taken from the paper.
We live in a world of Data. And as residents of the world of Data, we’d like to do analysis of said Data.
Simply put, analytical processing is an integral part of any data store. Online analytical processing (OLAP) queries aim to support multidimensional analysis at high speeds on large volumes of data. With frequent updates to databases, snapshots of the data need to be stored at the time that OLAP queries are issued so that concurrent updates to the database are not hindered. This is snapshot isolation.
The Problem
In an online database, with concurrently occurring transaction updates through OLTP (online transaction processing, OLAP queries issued at a given time requires a snapshot (‘image’) of the target data item at the time of issuance. Thus, the data store can continue serving OLTP queries while OLAP query analyses the stored snapshots.
Traditionally, SI (Snapshot Isolation) is implemented via multi-versioning: every update generates a new version of the data item; and previous versions are stashed as long as certain they are the target of an active OLAP query. Clearly, with multiple long-running OLAP queries, several versions of the data item being snapshotted may lead to what is known as space amplification, i.e., increase in the memory occupied by the data store.
Secondly, versions or snapshots that no longer belong to any active OLAP query need to be garbage collected. Maintaining many versions implies garbage collection needs to be done as frequently introducing latency spikes in performance.
The Solution
It is observed that analytic queries are very often commutative operations over ranges that need to read each item in a given range exactly once. Thus, introducing a new paradigm: OLCP (OnLine Commutative Processing).
Under OLCP, queries are processed on the same snapshot that they would observe under traditional multi-version SI, but space amplification and garbage collection latencies. In the event of any update, the older version is propagated to the corresponding OLCP queries instead of creating multiple versions in the store.
Two Key Observations
OLCP is enabled by two key observations in OLAP.
- Most OLAP queries scan data; but are not sensitive to the order in which they read items; in other words, they perform commutative operations.
- OLAP queries read scanned items at most once.
For example, consider any statistics query on a sales data store (say, most popular item in a region), which can be performed by scanning the sales record entries once in any order. OLCP works with scan ranges. When an item is updated by any OLTP update, its old value is propagated to all OLCP queries in whose scan range it was included in.
The immediate advantage is that we are avoiding the storage of an older value of the data item and thus, limited space amplification and garbage collection overhead is subsequently reduced. The second advantage is that since, OLCP processes data items as they are updated, they are read from the memory more oftenly than the disk (“cache-friendly”).
To keep the system complete, OLCP also supports point ranges that are processed as by a traditional SI using versioning. Combined with point ranges, OLCP allows the same expression power as standard OLAP queries; with the reduced space amplification, limited Garbage Collection-induced latency spikes and in general, higher throughput. However, there is a trade-off, OLCP queries can read items belonging to its scan range only once; and not necessarily in order.
Some Deets
OLCP queries are written in an interface inspired by the MapReduce paradigm. The format for an OLCP query is :
T = olcp_query(map, payload, [scan_range1, scan_range2, …], [point_range1, point_range2, …])
map is a callback function that is called exactly once on all items in the scan ranges.
payload refers to application-specific data for map callback to store and/or retrieve intermediary computation results.
scan_range(s) and point_range(s) have already been defined above.
olcp_query function blocks until the scans are complete. After calling olcp_query, a reduce function may be written to perform further processing on the payload.
Scan, Propagate and Reclaim
Let's go a little further in detail and take a look at how updates to databases affect OLCP query supporting data stores.
Whenever a new update arrives, the old version is added to the GC(garbage collection) queue(gc) and then the updated value is written to the key-value store(kv).
/*OLCP commit: create a new version and add the
old version in GC queue */
timestamp t_commit = now();
active_commit_timestamps.add(t_commit);
foreach(item i in updated_items) {
kv.write(i , t_commit);
gc.add(get_oldest(i), t_commit);
}
active_commit_timestamps.delete(t_commit);
Next, the gc queue is scanned and for each running olcp_query if, this version of a given queue element is included in the range for any olcp_query, then it is added to the propagation_queue of that query. Then the old version is removed from the data store.
/* GC */
timestamp t_min =min(active_commit_timestamps);
foreach(item i in gc) {
// Only delete items from
// fully committed transactions
if(i. t_commit >= t_min)
break;
foreach(olcp o in running_olcp) {
if(o.in_snapshot(i) && i. key > o. last_scanned)
o.propagation_queue .add(i);
}
delete(i); // remove from the store
}
In the olcp_query, the propagation_queue is scanned and the map is called on the propagated value if not already scanned. The get_next function is the procedure to request items in a lexicographic order. That is, in the absence of concurrent updates, all mappings will be done in lexicographic order via the get_next function. However, since in OLCP, concurrent updates are allowed. OLCP query checks for items that may have been propagated as a result of such updates and maps then first. Then the query resumes from the last scanned item via the get_next function.
/* OLCP query thread */
item last_scanned = get_first(scan_range);
do {
if(last_scanned != EOF) {
map(last_scanned, payload);
get_next(&last_scanned);
}
while(item i = propagation_queue .pop())
if(i. key > last_scanned)
map(i , payload);
} while(last_scanned != EOF);
The key to avoid space amplification with OLCP is to delete old versions of data items as soon as possible. But simple replacement is not enough; we cannot just delete old data and put new data. Once a data item is updated by an OLTP transaction, the oldest version of the data item is put on the GC queue. The GC deletes such items after due propagation to OLCP queries only if it belongs to the query’s snapshots.
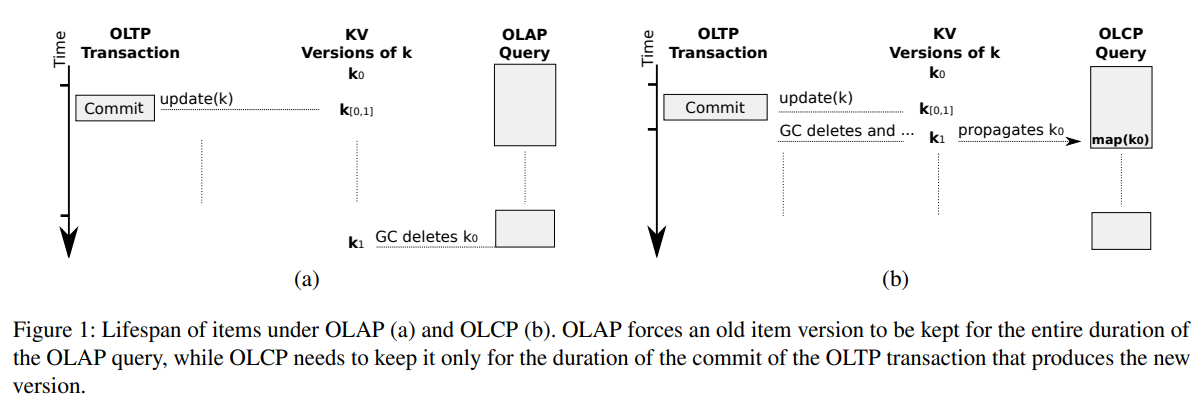
When an OLCP query does not use point ranges, a rough estimate of the number of versioned items in OLCP is the number of updates per transaction times the number of concurrent commits. In a conventional implementation of SI, this number is much higher, since the system needs to keep old versions of all items updated during the lifetime of OLAP queries. Older versions of data are only kept for the period they are absolutely necessary. See the figure below for comparison of OLAP and OLCP query version lifespans.
In Practice
Analytical processing is typically done in the following three ways: multidimensional OLAP (MOLAP), relation OLAP (ROLAP), and MapReduce-style analytics.
MOLAP stores are generally extracted and transformed into specialised cube format from relational databases. OLCP can reduce the space overhead of the extraction phase to store snapshots more efficiently.
ROLAP tools query the relational databases directly through SQL-like languages. There is a simple map-payload update transform for decomposable aggregate functions like SUM, COUNT, MIN, MAX, etc. For aggregations like GROUP BY and larger extensions CUBE and ROLLUP, similar map updates payload and an external reduce function that summarises the payload data.
Similar transformations to map-reduce format exist for SQL style joins, be it hash joins or nested loop joins.
In MapReduce style analytics, conventional SI can cause prohibitive space amplification since the scans there are in the order of a few hours with concurrent foreground write-heavy workloads. OLCP supports consistent one-pass scans with virtually no space overhead.
Results
The OLCP framework is implemented on top of KVell, a popular key-value data store. Some modifications need to introduced in KVell (in GC style and implementing propagation mechanism) which was called KVell+.
Steam, which is another method for reducing space amplification in SI systems, is also used in benchmarking. A consistent reduction in space-amplification and a rise in throughput was observed.
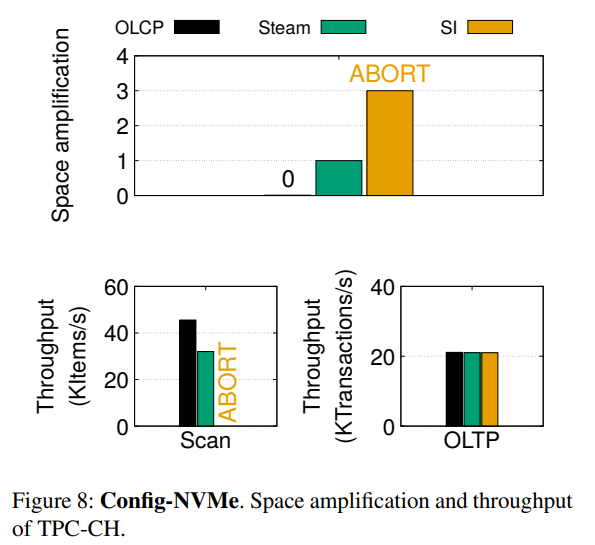
The persistence of the old versions of data items also drastically reduced across different workload environments. The OLCP lines in these figures are along the horizontal axis(!) compared to SI(conventional Snapshot Isolation using multi-versioning) and Steam.

Conclusion
Long OLAP queries which would otherwise lead to a large space amplification and undesired transactional update latencies, are now processed through OLCP that provides the same isolation guarantees as conventional SI but with much better space optimization and much lesser interference with concurrent OLTP updates.
Operating System Support for Safe and Efficient Auxiliary Execution
Applications in production typically need maintenance to check, refine, troubleshoot, and regulate how they operate. In the past, administrators worked mostly manually on maintenance. Applications need to be able to self-manage and give strong observability more and more often today.
These tasks are intended for a variety of purposes, such as fault detection, performance monitoring, online diagnosis , resource management, and so on. For example, PostgreSQL users can enable a periodic maintenance operation called autovacuum that removes dead rows and updates statistics; MySQL provides an option to run a deadlock detection task, which tries to detect transaction deadlocks and roll back a transaction to break a detected deadlock; HDFS server includes multiple daemon threads, such as a checkpointer that periodically wakes up to take a checkpoint of the namespace and saves the snapshot.
The main and auxiliary are the two logical areas of activities that make up the framework of applications (Figure below). The latter responsibilities are crucial for the dependability and observability of production software.
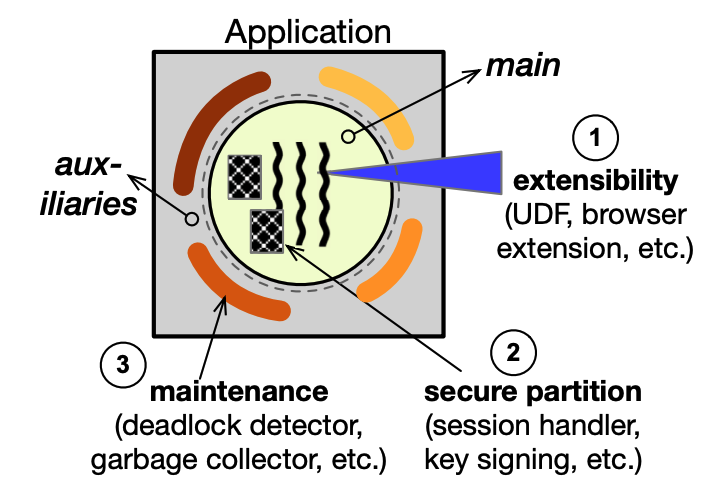
So what is the problem then ???
Modern applications run various auxiliary tasks. Executing these operations in the application address space gives them considerable observability and control, but doing so compromises safety and speed. Strong isolation is provided by running them in distinct processes, but control and observability are compromised.
At the implementation level, the execution of auxiliary tasks is mixed with that of the main programme in the same address space, either through direct function calls or through the use of threads. Due to excessive blocking and resource congestion on the CPU, memory, network, and other resources, this decision unfortunately means that the auxiliary tasks might have significant interference with the execution of the application. Bugs in the auxillary task might easily damage the application dependability in addition to expenses.
A trivial solution that comes to mind is to execute an auxiliary task externally in another process. But this would mean giving precious computing rescources to auxillary tasks if they are run as external processes. Further it limits the power to observe and change main task execution.

Why not use forks or sandboxing?
Fork-based Execution Model
In this approach, the application makes a fork() system call before an auxiliary task executes and switches to run the task functions in the child process. Unfortunately, there are several issues. First, the cost is substantial, which includes the creation of a heavy-weight execution entity, as well as the copying of an address space.Besides overhead, with the auxiliary task running as a child process, it is difficult for the task to perform maintenance work that requires modifying the main program states.
Sandbox-based Execution Model
Another solution is to execute an auxiliary task in a sandbox, which is well-suited to execute untrusted code. However, auxiliary tasks are not untrusted codes that sandboxes are designed for. They are written by the application developers and are trusted. Their safety issues arise because of bugs or unintended side effects such as invalid memory access, infinite loops, using too much CPU, etc., rather than accessing unwanted system calls or files.
Orbit: the savior
Developers are forced to choose either an abstraction that offers high observability but weak isolation (e.g., thread), or one with strong isolation but low observability (e.g. process). Orbit is an OS support for auxiliary tasks to address this challenge with an abstraction. Orbit supports the following features-
- Fault detection
- Performance monitor
- Resource management
- Recovery
Many auxiliary duties are performed by modern apps. Executing these operations in the application address space gives them considerable observability and control, but doing so compromises safety and speed. Strong isolation is provided by running them in distinct processes, but control and observability are compromised. While running in its own address space, each orbit periodically checks the condition of the main programme. The orbit abstraction offers a crucial feature of automatic synchronisation for the referenced state to promote straightforward examination. From the main address space to the orbit's address space, this automatic synchronisation is one-way.
When an orbit is established, it waits for orbit calls to be made by the main programme. Because each call spans two address spaces, implementing the task execution is challenging. Additionally, various orbit calls, including concurrent calls, may be made to the orbit. These various styles must all be supported by the kernel side. The kernel keeps a task queue for each orbit to handle potential concurrent calls. The kernel creates an internal call struct and assigns a call id to each invocation from the main programme before adding it to the queue. The pending invocations are dealt with in FIFO order by the orbit task execution workflow. It is significantly easier to verify that the state synchronisation is accurate when the task invocation processing is serialised.
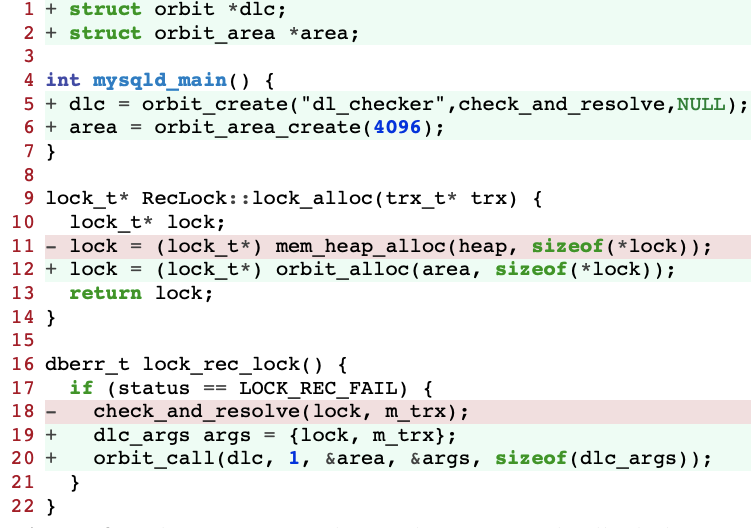
Implementation of Orbit
The authors develop a helper mechanism called orbit task return to effectively execute orbit task execution. As seen in Figure 6, each orbit executes this loop as a single-threaded worker and calls this system call once for each iteration. The kernel checks the data in its orbit info to determine which main programme this orbit relates to when it gets trapped inside the orbit task return syscall. This kernel function is split into two parts on the inside. It sends the return value from the most recent orbit call to the main programme in the first half. The kernel specifically notifies the thread that was performing the last orbit call and blocked while waiting for the call to complete. It then saves the provided ret value into an internal struct corresponding to the last orbit call. This initial portion is omitted if no orbit call has been received.
The function waits for the next job from the main programme in the second part. The orbit control block's semaphore is used for this purpose. The orbit task return moves forward and dequeues an invocation as soon as the orbit tasks queue is not empty. Recall that state snapshotting keeps the indicated PTEs for the next invocation in an array (Section 4.3). The PTEs are now installed into the orbit's page table by the kernel function, which is now applying the snapshot. After that, it returns after setting up the userspace argbuf and func ptr.

- Strong Isolation
- Convenient Programming Model
- Automatic State Synchronization
- Controlled Alteration
- First-class Entity
Limitations of Orbit
- Leads to costly page faults to mantain state synchronization
- Compared to programming with threads, using orbit requires the additional effort to properly change some allocation points
- It does not prevent an auxiliary task from sending an incorrect update back to the main program and cause the main program to malfunction
KSplit: Automating Device Driver Isolation
A significant amount of flaws and vulnerabilities present in modern kernels originate due to device drivers. Drivers are expected to support a wide range of sophisticated protocols and kernel conventions for ensuring concurrency and asynchronous accesses on multiple CPU cores present in modern systems.
When a device driver gets installed in our system, they appear to us as something that magically supports the device operations out of the box. But just try to imagine the complexity that the driver has to undergo to support every operation smoothly and more importantly without compromising the safety of the system.

What is KSplit?
KSplit is a new framework for isolating unmodified device drivers in a modern, full-featured kernel built using several existing frameworks or techniques to achieve its purpose. KSplit conducts automatic analysis on the kernel and driver's unmodified source code to
- detect the shared entities between the kernel and driver while it is operational.
- compute the synchronisation requirements for these shared parameters for achieving isolation of the driver.
Why KSplit?
Although low-overhead device isolation frameworks are now feasible due to the recent development of hardware features but isolation of device drivers is not an easy task. The shared memory environment in which the kernel and the driver operates makes it extremely challenging as they exchange references to complex data structures (like hierarchial, cyclic data structures having a lot of data and pointers).
To determine how the complex state of the system is accessed on both sides of the isolation boundary, it is necessary to carefully analyze the flow of execution between isolated subsystems before isolating a driver. And this requires a lot of manual analysis of legacy driver code to detect the kernel-driver dependencies. Many researchers proposed several methodologies to automate this analysis but such frameworks only address a small fraction of the task.
Manual analysis in this context becomes impractical due to the increasing volume and complexity of modern drivers. For example, a complex network driver in linux, ixgbe requires analysis of 5,782 functions and over 900,000 object fields - a number that is beyond the reach of manual analysis. Existing research works on automating these works concentrated on techniques to isolate only that portion of driver functionality that could be executed effectively in isolation. Due to this, many drivers' components such as interrupt handlers were still housed in the unisolated kernel.
Here KSplit comes into picture. It performs a static code analyses of kernel and the driver and proposes efficient methods to automatically detect the shared state that is accessed by the kernel and the driver and determines how it should be synchronised. In case of ambiguity, it indicates the programmers for manual intervention.
The Solution
KSplit transforms a device driver working on top of shared memory for communication with the kernel into an equivalent driver which can operate in an isolated environment on a separate copy of the driver state. Moreover, it identifies the common sub-state which is used by both the kernel and the driver for designing an isolation boundary and tries to derive how this state can be synchronized between that isolation boundary. It even supports the concurrency control methods such as spinlocks, atomics, mutexes, ready-copy-update(RCU) etc.
Let us understand how KSplit works with an example to see what actually happens under the hood.
The Linux Kernel sends a network packet to a network device with the ndo_start_xmit() function which has the following structure:
ndo_start_xmit(struct sk_buff *skb, struct net_device *netdev)
As we can see there are two input arguments skb and netdev. So, what KSplit ensures is that all the fields shared between the kernel and driver of all the data structures that are recursively reachable from the two input arguments (skb and netdev), and all
global kernel variables, are synchronized with the driver. Once the invocation to the driver gets finished, the fields in these data structures, modified by the the driver are synced back to the kernel. KSplit also synchronises the driver's state with the kernel on entry and exit from the atomic region to prevent data corruption when the driver code uses a concurrency primitive that is shared with the kernel, such as a global lock, like the rtnl_lock used by network device drivers to register with the kernel.
So how does KSplit achieve all these things magically? Basically, it provides its own software analysis algorithms to achieve these tasks. Let us take a deeper look into that.
Kernel data structures often consist of a large number of fields that may be referenced during the invocation of a driver. For example, The sk_buff structure which we came across earlier, has the definition as shown below:
struct sk_buff {
struct net_device *dev;
unsigned int len, data_len;
u8 xmit_more:1;
...
sk_buff_data_t tail;
sk_buff_data_t end;
unsigned char *head, *data;
unsigned int truesize;
};
It represents a network packet which consists of 66 fields (5 pointers and 2 offsets) through which 3132 fields (1,214 pointers) are recursively reachable in other data structures.
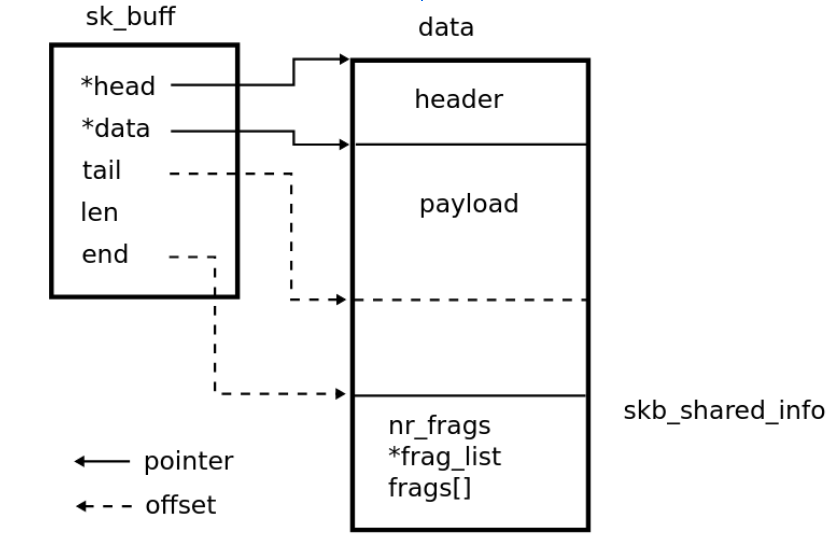
However, the kernel works only on a small fraction of these shared fields(52 fields). Now, how will KSplit identify these subfields and generate an interface to isolate the device drivers based on these shared state information? Here, KSplit employs an intelligent end-to-end pipeline for device driver isolation.
Workflow
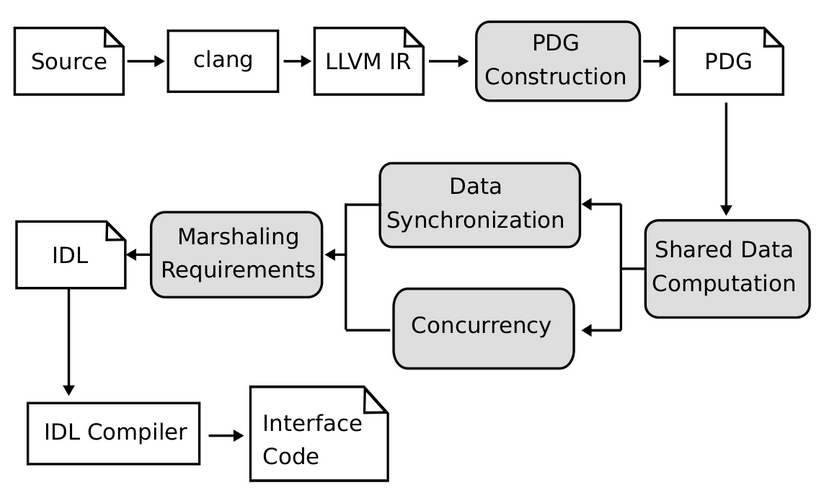
KSplit takes the source code (i.e., the code of the kernel and a device driver) as input, and converts it into LLVM IR using Clang.
Then it uses a field-sensitive data-flow analysis along with a modular alias analysis to identify the field references shared by the kernel and the driver for detecting their shared state. It generates a program dependence graph [PDG] to understand the connections between the kernel and the driver code. PDG helps to capture control and data dependencies between instructions. Further it applies a parameter tree approach to scale alias analysis. "Alias" is a set of variables or expressions which point to the same memory location. Hence, identifying these aliases becomes important to understand the shared states. To retrieve all such data structures that require synchronization, the authors propose a new algorithm called "Parameter Access Analysis".
To support concurrency and data synchronization, KSplit relies on combolocks to preserve synchronization across isolated boundaries for critical sections which require a lock. For lockless atomic operations, drivers call the kernel to update its primary copy of the data which is maininted in the kernel.
Finally, KSplit generates rich IDL(Interface Description Language) annotations that provide support for marshaling of several low-level C idioms(such as Tagged unions, recursive data structures, wild pointers etc) which can generate ambiguity during static analysis. For every function crossing the boundary of an isolated domain, an IDL remote procedure call declaration is generated. For the ambiguous sections which are not automatically resolvable, KSplit generates a separate IDL warning to indicate requirement of manual intervention in interface code generation. In this way, the device driver get isolated.
Several results on static analysis and their performance metrics in different stages of the workflow of KSplit were compiled in the paper. We will look into the impact of KSplit on one specific case for the network driver that we discussed above.
Impact on Ixgbe Network Driver Isolation
KSplit was able to automatically resolve all function pointers that ixgbe registers with the kernel as its interface. Further it identified five user and ioremap memory regions used by the interfaces of the driver. Out of 143 wild void pointers that ixgbe shares across the isolation boundary only 1 required manual intervention. The isolation process of the driver required manual inspection of 27 array pointers (out of 119 exchanged across the boundary).
Conclusion
In this work, we observe that KSplit enables the isolation of sophisticated, fully functional device drivers with the least amount of human intervention. Given the fact that modern hardwares are migrating toward providing solutions for low-overhead isolations, the main challenge that remains in such task is the complexity of the driver interfaces. Although, the authors argue that their method is generic, it is yet to stand the test of time whether KSplit actually generalizes well for different kernels and operating systems.
CAP-VMs: Capability-Based Isolation and Sharing in the Cloud
Motivation
Cloud stacks need to isolate applications while providing efficient data sharing between different components deployed on the same physical host.
The Memory Management Unit (MMU) typically enforces isolation and allows sharing at the page level. However, the involvement of the MMU leads to large TCBs in kernel spaces, and page granularity requires inefficient OS interfaces for data sharing.
In cloud environments, isolation is ensured using VMs and containers. When application components interact with each other heavily, there the VMs and containers add considerable overhead.
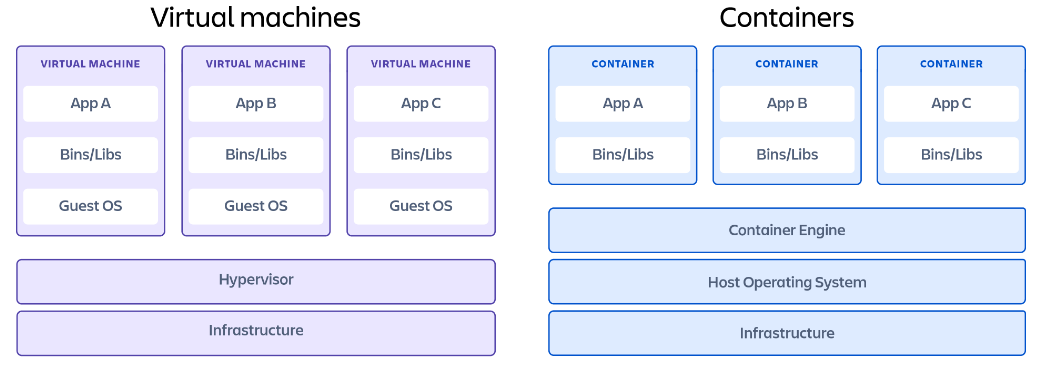
Since VMs have their own OS kernels, their TCB can be reduced to a smaller hypervisor, that handles VM access to the hardware. But, efficient inter-VM data sharing becomes difficult, due to performance and page granularity trade-offs.
Containers are lightweight software packages that contain all the dependencies required to execute the contained software application. The dependencies included in a container exist in stack levels that are higher than the operating system. They provide faster inter-process communication methods, like pipes, shared memory, and sockets. This comes at the cost of large TCB, also having a shared OS kernel below also increases the chance that an exploit in one container could impact the shared hardware by escaping the container.
So, we observe that in the existing cloud stack, there is always a tradeoff in performance while trying to isolate components and communicate between them.
CAP-VMs
Here, we discuss CAP-VMs (cVMs), a new VM-like abstraction for executing isolated components and sharing data across them. cVMs employ hardware support for memory capability to isolate components and offer effective data exchange.
Using memory capabilities in the cloud stack has some challenges associated with it:
-
It should support pre-existing capability-unaware software without major changes in codebase or compilers.
-
Remain compatible with existing OS abstractions like the POSIX interface.
-
Offer IPC-like methods to share data safely between untrusted components.
To address the above points, the cVMs makes some design contributions. We look at each of them in detail.
-
Multiple cVMs share a single virtual address space safely through capabilities. Each cVM has a pair of default capabilities to ensure all accesses happen within its memory boundaries.
-
They have a library OS with POSIX interfaces, making them self-contained and reducing reliance on the external cloud stack. In the library OS, each cVMs implement its own namespaces, virtual devices, etc.
-
cVMs offer two low-level primitives, i.e, CP_File API, and CP_Call API, to share data efficiently without exposing application code to capabilities.
Existing Cloud Stack - Features and Flaws
For a moment, let's revisit containers and virtual machines (VMs), which are frequently utilized in cloud applications.
VMs and containers are compatible with existing applications, which is critical in cloud environments. But the compatibility offered by these technologies lowers communication performance. Despite strict isolation between the memory of containers, there is a lack of isolation of the TCB that manages the virtualization mechanism. Due to the fact that they share kernel data structures, containers are more vulnerable to security threats, and privilege escalation in one container can have an impact on all other containers. VMs are virtualized through a narrower interface and are harder to compromise but this comes at the cost of performance price. Components in a cloud system typically communicate through networking using some reliable network protocol like TCP, even if they are co-located on the same machine. This adds overhead for co-located components.
How do cVMs get around these problems
cVMs make use of CHERI architecture, which implements capabilities as an alternative to traditional memory pointers. A capability is stored in memory or registers, and encodes an address range with permissions, e.g., referring to a read-only buffer or a callable function. CHERI is used to compartmentalize software components, by giving each memory region separate capabilities. This ensures that components can co-exist in the same address space.
The cVM architecture is given in the following figure. Each cVM is an application component, such as a process or library, and has three parts:
-
Program binaries and their libraries
-
A standard C library
-
A library OS.
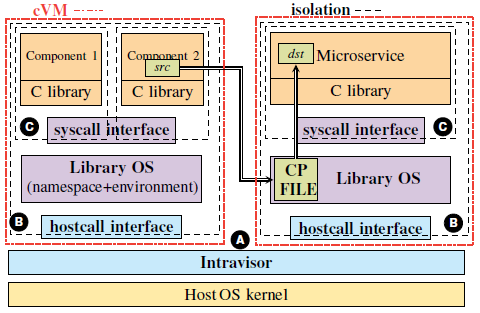
cVMs enforce isolation boundaries by CHERI capabilities. Compartmentalized content cannot access memory beyond its boundary, except through the controlled interfaces. There has been a set of APIs provided, which are implemented using CHERI capabilities, for efficient inter-cVM communication. You can go through them in the following figure.

We also desired that the application code not require a significant rewrite in order to make it capability-aware. The Intravisor, which explicitly handles API calls using syscall trampolines, the library OS, and a tiny amount of the standard C library are the only pieces of code that are capable-aware in the cVM design.
Implementation
We now look a bit into the implementation of cVMs.
Initialisation: The boot process of a cVM is triggered by the Intravisor. It receives deployment configuration containing details about heap size, disk image location, and information about the Init service. The Init service initializes all the components at the time of deployment and creates the communication interface between the library OS and the host system. It initialises the library OS. It also constructs the program's (or library's) syscall interface, deploys its binary, and runs the entry function.
Execution: cVMs uses Linux kernel Library as library OS that provides a Linux-compatible environment. LKL processes system calls and requests the host OS kernel to perform actions as needed.
Threading: cVMs employ a 1-to-1 threading model for simplicity. When a thread is created by cVM, the pthread library requests an execution context from LKL, which in turn, requests a new thread from the host OS kernel.
Calls between nested compartments: For calls between nested layers, cVMs use two types of calls:
-
From an outer to an inner layer (ICALL), e.g., when the Intravisor invokes init
-
From an inner to an outer layer (OCALL), e.g., when performing syscall
Communication Mechanism: The data sharing API between cVMs is also based on capabilities. The data reference by capabilities can be manipulated by capability-aware instructions, but the application code is not capability aware. To handle this, cVMs make use of virtual devices called CAP devices. A program reads/writes from these devices, and the device handle the manipulation using capability-aware code.
Conclusion
So here we covered the idea behind cVMs and how they are a different approach to isolation and sharing in the cloud. cVMs make the use of capabilities to overcome the performance issues in inter-process communication that come with the large TCBs in VMs. They also provide communication APIs and do not require application code to be capability aware. They provide fast inter-communication with good isolation.
Overall, I feel like cVMs are an interesting, fresh approach to isolation in the cloud architecture. They provide increase performance but I have the opinion that cVMs are prone to security attacks as capability-based system by-pass the context switch to privileged mode.